[TIL 6th] SQL 완강-빠르게 핥은 SQL / 애증의 group by
by 노실언니진행상황
Complete | `웹개발종합반` 완강
Complete | `엑셀보다 쉽고 빠른 SQL` 완강
In progress | 국민취업지원제도 1유형 | 1단계 취업활동계획 수립기간 中
11/12 신청 → 11/25 확정 → 1단계 취업활동계획 수립기간 (센터방문상담 3회: 11/28, 12/5, 12/12)
In progress | 내일배움캠프 Spring 5기 사전캠프 (24.11.18.月 ~ 24.12.20.金─총 33일 / 14:00~18:00 ─일일 4시간)
In progress | SQL 강의 퀘스트 하기
In progress | 혼공자바 읽기 & 퀘스트 하기
To-do | 내일배움캠프 Spring 5기 본캠프 (24.12.23.月 ~ 25.05.06.火 ─총 135일 / 9:00~21:00─일일 12시간)
To-do | C++ 자료구조, 알고리즘 책 읽기
To-do | 얄코의 HTML/CSS/JS 책 읽기
To-do | C++ 자료구조, 알고리즘 책 읽기
To-do | DB 입문/실무 - 국민대 김남규 교수님 강의 듣기 & SQLD자격증챌린지 & SQL 자격검정 실전문제 풀기
드디어 완강


이 강의를 통해서 배운 것들
① DB와 SQL의 정의에 대해 간.단.하게 배웠다. → 쉽게 비유적으로 정의해주셨다 :D 좀 더 정의를 찾아보고 싶다.
② SQL문의 기본 구조인 SELECT, FROM, WHERE, GROUP BY, ORDER BY 를 배우고 실습 및 과제를 진행했다.
→ SELECT 컬럼 선택 / FROM 테이블 선택 / WHERE 값 필터링 / GROUP BY 값 그룹화 / ORDER BY 정렬기준설정
③ 기존 컬럼(column)의 값을 변형해서 새로운 컬럼을 만드는 법을 배웠다. [SELECT]
- 컬럼 이름(별칭) 짓기 : 컬럼명 AS 이름 (컬럼 뿐만 아니라 테이블명에도 사용됨)
- 값 일부 교체 : replace(대상 컬럼명, 대상 값, 교체 값)
- 값 일부 발췌 : substring(대상 컬럼명, 시작 인덱스, 글자수) ⛦ 1부터 시작
- 값 연결 : concat(컬럼명 혹은 값1st, 2nd, · · · )
- 값 혹은 컬럼끼리 사칙연산 : + - * /
- 조건부변경 if (적용할 컬럼명과 조건, 참일 시 값, 거짓일 시 값)
- 조건부변경 case when 적용할 컬럼명과 조건 then 참일 시 값 ··· else 그외의 상황일 때의 값 end
④ WHERE절과 IF문 혹은 CASE문에 사용되는 다양한 조건식과 연산자를 배웠다. [SELECT/WHERE]
- 같다 다르다 이하 미만 초과 이상 = <> <= < > >=
- v1이상 v2이하인가 : between val1 and val2
- 특정 값을 포함하는가 : in (v1, v2 · · ·)
- 특정 문자를 포함하는가 : like " %문자% " (%: 아무문자)
- null 인지 아닌지 : is null is not null
- 논리연산 : and or not
⑤ 한 컬럼의 모든 값(행)으로부터 하나의 결과값 혹은 그룹별 결과값을 반환하는 Aggregate Function을 배웠다. [SELECT]
- 값 갯수 리턴 COUNT(* 혹은 컬럼명) 🚨*을 쓰면 NULL값도 세고, 그 외는 NULL값을 세지 않음
- 값 종류 갯수 리턴 COUNT(DISTINT 컬럼명)
- 총 합, 평균, 최대값, 최소값 리턴 SUM, AVG, MAX, MIN (컬럼명)
- 모든 값이 아닌 다른 컬럼의 값이 같은 것끼리 그룹화하여 계산하고 싶을 때 ▶ GROUP BY 기준 컬럼명/select 속 컬럼인덱스
⑥ Query 수행의 결과(테이블)를 다시 Query에 활용하는 SUBQUERY 개념을 배웠다.
- ( query를 )로 묶고 as 로 별칭 주기
+ 서브쿼리의 장/단점이 궁금하다
⑦ 정렬하는 법을 배웠다. → ORDER BY 컬럼명 (desc까지 쓰면 내림차순)
⑧ 기준 외의 값을 거르고 싶을 때 어떻게 해야하는지도 배웠다.
- 간단하게 WHERE절 사용하여 거르기
- SELECT절에서 조건문으로 원치 않는 값을 null로 변경 & WHERE 컬럼명 is not null 로 거르기
- coalesce(컬럼명, 대체할 값)을 사용하여 null 값을 다른 값으로 변경하기
⑨ 여러 쿼리를 한 줄 이상의 공백으로 구분해두면, 후에 원하는 쿼리문에 커서를 둬서 해당 쿼리만 실행시킬 수 있다는 걸 배웠다.
⑩ 두 테이블에서 값의 종류가 동일한 컬럼을 기준으로 두 테이블을 연결하여 새 테이블을 만드는 JOIN 개념을 배웠다.
- FROM 기준 테이블명 as 별명1 LEFT/INNER JOIN 연결할 테이블명 as 별명2 ON 별명1.컬럼명 = 별명2.컬럼명
- INNER JOIN : 기준 테이블의 컬럼 값이 연결할 테이블의 컬럼 값에 없는 경우, 해당 행은 테이블에서 제외함
+ 배울 땐 이해가 안 갔는데, 오히려 지금 이해가 가는 듯
⑪ max와 if 문을 사용하여 Pivot table 수제로 만드는 법을 배웠다.
- 기본적인 테이블 모습 → 첫 행에 컬럼명이 있고 두번째 행부터는 관련 값이 주르륵
- 피벗 테이블의 모습 → 첫 행/첫 열이 두 컬럼의 값 종류 속성의 관계성이 잘 보이는 테이블
+ 쪼금 더 분석하기
⑫ 특정 컬럼값이 같은 행끼리(그룹화), 다른 컬럼값에 대한 순위를 매기는 컬럼 만드는 법을 배웠다.
- Window_function (컬럼명) over (PARTITION BY 컬럼명 ORDER BY 컬럼명 asc/desc) as 컬럼명
- RANK() OVER (PARTITION BY 그룹 컬럼 ORDER BY 기준 컬럼 desc쓰면 내림차순) AS 새 컬럼명
+ 더 써봐야 알듯
⑬ 특정 컬럼값이 같은 행끼리(그룹화), 다른 컬럼값을 전부 더하는 혹은 누적해서 더하는 컬럼 만드는 법을 배웠다.
- Window_function (컬럼명) over (PARTITION BY 컬럼명 ORDER BY 컬럼명 asc/desc) as 컬럼명
- select sum(컬럼명) → 해당 컬럼의 모든 값을 더해서 하나의 값 출력
- select sum(컬럼명1) + group by 컬럼명2 → 컬럼명2의 값이 같은 행끼리 컬럼명1의 값을 더하여 출력
- select sum(컬럼명1) over (partition by 컬럼명2) → 컬럼명2의 값이 같은 행끼리 컬럼명1의 값을 더하여 출력
- select sum(컬럼명1) over (partition by 컬럼명2 order by 순서의 기준인 컬럼여러개 가능 desc쓰면 내림차순)
→ 컬럼명2의 값이 같은 행끼리 컬럼명1의 값을 더하는데, 한번에 더하는게 아니라
특정 컬럼값의 오름차순/내림차순 기준으로 더하여(=누적합) 출력
⑭ 마지막으로, 날짜/시간 데이터의 형식을 변경하는 법을 배웠다.
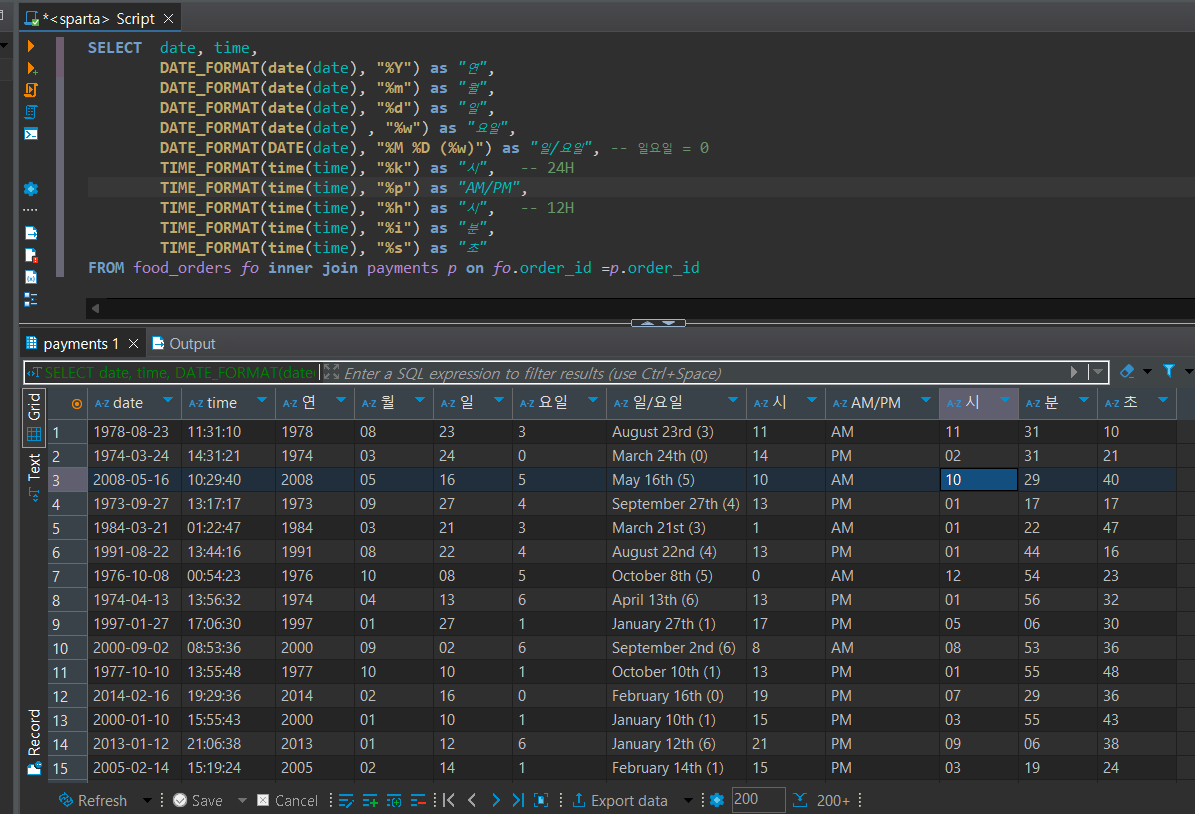
이어 할 일 고민
내가 들은 SQL 강의는 이전에 들었던 웹강의처럼 전부를 얉게 훑은 느낌이고, DB제작, DB읽기, DB에 값 추가하고 변경하고 지우기 중에서 읽기에 포커스를 맞춘 강의였다. 덕분에 많이 모르는 상태에서 읽을 수는 있는 정도가 되었다.
데일리 스크럼을 하면서 DB에 대헤 조금 더 잘 알고 싶고 특히 Join에 대한 감이 잡히지 않는다고 말했었는데, 조원분께서 국민대 교수님의 DB강의를 추천해주셨다. 많이많이 괜찮은 강의였다. 울 학교 DB수업들을 때 잘 들을껄 ㅜㅜ
해당 강의를 보고 실전문제집도 풀어서 SQLD자격증도 따보고 싶어졌다. 취업 관점에서는 크게 의미 없겠지만, 자격증은 나에게 공부 연료가 되어주는 느낌이니깐 말이다.
대신, 부트캠프에서 부여받는 일들이 더 우선이니깐 이 욕심도 지금은 미뤄둬야겠다.
찐하게 복습하기 ① DB, SQL 관련 정의
Database란?
데이터의 조직화된 모음이다. 일반적으로는 행과 열로 정돈된 일련의 테이블 형태(Relational DB)로 모델링 된다.
Database는 일반적으로 DBMS(Database Management System)에 의해 제어된다.
Database 사용자는 DBMS가 인식할 수 있는 언어로 Query(요청)문을 작성하여 데이터를 쿼리, 정의, 조작, 제어할 수 있다.
DBMS(Database Management System)란?
성능을 모니터링하고, 튜닝하고, 백업/복구하는 등 Database를 관리하는 소프트웨어 프로그램이자,
DB와 사용자(거의 응용프로그램) 간의 인터페이스 역할을 하여 사용자가 DB를 생성, 검색, 수정, 최적화 등 DB를 제어할 수 있도록 하는 소프트웨어 프로그램이다.
DBMS 덕분에 여러 곳에서 데이터를 공유하고 데이터에 접근해도 문제가 생기지 않는다.
DBMS의 종류에는 MySQL, Oracle, MariaDB, PostgreSQL, MS ACCESS, SQLite 등이 있다.
MySQL 이란?
SQL기반의 RDBMS(Relational Database Management System)이다.
실습에 사용한 DBMS !
SQL(Structured Query Language)이란?
데이터에 대한 쿼리, 조작 및 정의, 접근제어를 위해 사용되는 일종의 언어로, 대부분의 Relational Database에서 사용된다.
SQL은 국제표준화기구에서 하나의 표준을 정하지만, DBMS 제작사는 이 표준 SQL에 자신들의 DBMS 특성/기능을 반영한 새로운 문법을 더하여, 다양한 SQL이 존재한다. (표준SQL, Oracle의 PL/SQL, MySQL의 SQL,MS SQL Server의 T-SQL)
* 참고 사이트
찐하게 복습하기 ② Subquery의 장단점
단점 → 비용증가와 최적화불가
1) 이미 존재하기 때문에 불러오기만 하면 되는 Table과 달리 요청할 때마다 계속 연산해야한다. = 연산비용↑
2) Table과 달리 메타정보가 없어 최적화도구가 무용지물이다.
∴ Window function을 사용할 수 있는 상황이면, Subquery보단 해당 함수를 사용하자
장점(필요성) → JOIN의 연산비용 줄이기
불필요한 연산을 만들 행을 Subquery로 필터링한 후 JOIN 연산하면, 연산비용을 줄일 수 있다.
* 참고 사이트
[SQL] 성능 관점에서의 서브쿼리(Subquery) - 소라고동
[SQL] 성능 관점에서 보는 결합(Join) - 소라고동
찐하게 복습하기 ③ 수제 Pivot table 만들었던 코드 다시 살펴보기
[만들어야 하는 표와 필요한 테이블 파악]
- 만들고 싶은 표는 연령그룹(10~50대) 당 성별(남성/여성)별의 주문건수이다.
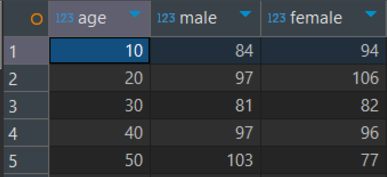
- food_orders 테이블에는 주문번호를 Key로 하여 각 행에 주문자ID값과 그 외 주문정보의 값들이 담겨있다.
- customers 테이블에는 주문자ID를 Key로 하여 각 행에 주문자 성별, 나이에 대한 값 등이 담겨있다.
[계획: Subquery 작성]
1. "주문건수" 가 최종 값이므로 주문내용이 담긴 food_orders 테이블을 기반으로 count를 사용하여야 한다.
- 따라서, join 연산 역시 위 테이블을 기반으로 한다.
2. join 컬럼: food_orders의 주문자ID와 customers의 KEY인 주문자ID를 기준으로 join 하여야 한다.
+ join연산시, customers테이블에서는 주문자ID, 성별, 나이 컬럼만 필요하다 (그 외는 선 subquery로 날려도 됨)
3. 첫 쿼리(Subquery)의 결과에는 성별gender, 나이그룹age, 주문건수count가 있어야 하고 Key 컬럼은 없어야 한다.
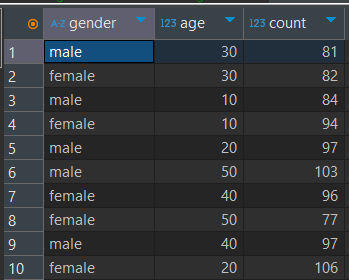
- 이렇게 되려면, JOIN한 결과로부터(FROM) 성별, 10단위로 끊은 나이, 주문건수(count) 컬럼을 만들고 (SELECT)
또한, 주문건수의 count는 전부 세는 것이 아니라 같은 성별×같은 나이끼리 세어야 하므로 GROUP BY를 사용해야 한다.

[계획2: Pivot 형태로 변경하는 쿼리 작성]
1. gender, age, count 컬럼이 있고 key가 없는 위 쿼리의 결과를 Pivot 형태로 바꾼다는 건
age 컬럼이 KEY이고 기존 gender 컬럼의 값 종류를 컬럼명으로, 해당 컬럼들의 값은 주문건수인 형태로 변형해야 한다는 것
(gender 컬럼 사라짐→ 값이 새 컬럼명이 됨 + count 컬럼은 사라지고, 새 컬럼들의 값이 됨)
2. age를 첫 컬럼으로 두는데(SELECT), Key가 되어야 하므로 해당 컬럼을 GROUP BY 한다.
3. SELECT에 gender 값 종류(male, female)를 컬럼명으로하여 새 컬럼을 생성해야 한다. - age로 group by 되고 있는 것도 염두
4. 새로운 male/female 컬럼의 값은 서브쿼리 속 gender 컬럼의 값이 male/female 인 행의 count 값을 넣어야 한다.
(male이라면 female의 count값은 제외되어야 함 → 이걸 어케 구현? IF와 MAX로 구현함 👍👍👍👍👍)
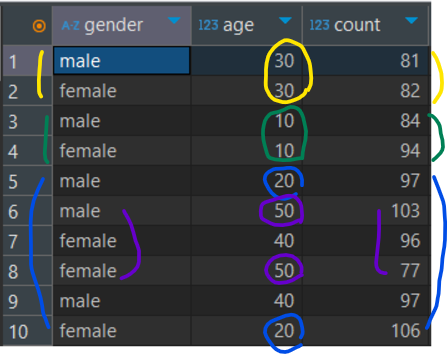
5.구체적으로 male/female 컬럼만들기 : 서브쿼리에서 같은 age끼리 행을 묶은 후(GROUP BY), gender 컬럼의 값이 male인 행은 count값, female인 0값을 가져온 후(IF) 이 중 큰 값을 자신의 값으로 한다.(MAX) ··· 오뚜케 이런 생각을 하지?
max(if(gender='male', order_count, 0)) male,
max(if(gender='female', order_count, 0)) female[결과]
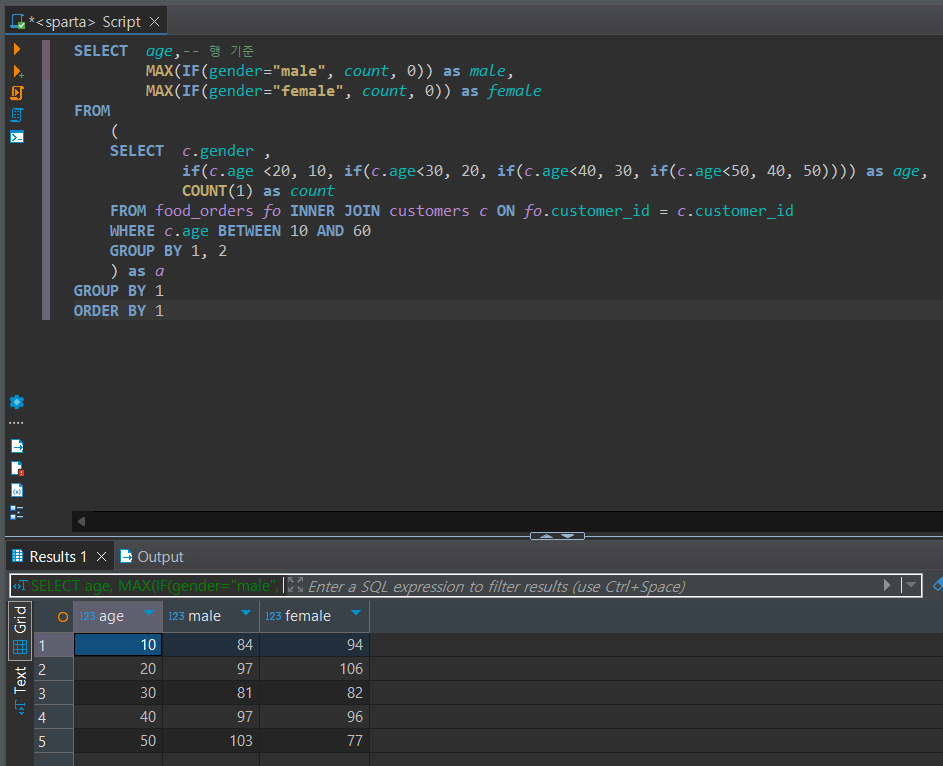
끝
'Today I Learned' 카테고리의 다른 글
| [TIL 10th] 코드카타 까먹은 코드들 / 파이어베이스 쿼리사용법 / 협업시 유의점 (0) | 2024.12.30 |
|---|---|
| [TIL 7th] Spring 5기 온보딩 | 배운게 없는데 많달까 (1) | 2024.12.23 |
| [TIL 5th] 웹개발종합반 완강/오타와 배포는 괴로워 (2) | 2024.11.29 |
| [TIL 4th] 웹개발종합반 3주차의 과제를 해보았다 (0) | 2024.11.22 |
| [TIL 3rd] 실제 기상청 Open API를 사용해보았다 (1) | 2024.11.21 |
블로그의 정보
노력하는 실버티어
노실언니