프로그래밍기초 Intro to Python 총정리
by 노실언니[ 계속 도움받은 사전같은 사이트 ]
2. Lexical analysis [ 영 ] [ 한 ]
7. 단순문(Simple statements) [ 영 ] [ 한 ]
8. 복합문(Compound statements) [ 영 ] [ 한 ]
★
프로그래밍기초Course
- 프로그래밍 시작하기-Getting started with python - 📺 📝
- 프로그래밍 핵심개념-Core concept of python programming - 📺 📝
- 프로그래밍과 데이터-Python programming and data - 📺 📝
- + 복습: ①자료형분류와 가변성 ②관련함수
- Python 응용하기-Making use of python - 📺 📝
*Link : 📺인강 📝정리노트
10년 안에 프로그래밍을 모르면 문맹이 되는 시대가 올 것입니다. 인공지능, 로봇, 사물인터넷, 가상현실, 스마트카 등 다가오는 미래 산업에 프로그래밍을 빼고 말할 수 있는 것은 없습니다. 그렇다면, 어떤 언어로 시작하는 게 좋을까요? 코드잇에서는 파이썬을 가장 추천합니다. 파이썬은 실리콘벨리를 비롯 세계 유수 기업에서 가장 많이 쓰는 언어이며, 미국 대학 상위 39개 컴퓨터 학과에서 선호하는 언어 1위이기도 합니다. 데이터 사이언스, 웹 개발 등 어디 하나 빠지지 않고 쓰이지요. 파이썬과 함께 프로그래밍의 세계에 첫 걸음을 내딛어 보세요.
→ Python을 배우면서 프로그래밍 자체도 배워보자


Topic 1. 프로그래밍 시작하기
프로그래밍의 진입 장벽이 너무 높게 느껴진다면? 파이썬으로 프로그래밍을 시작하세요!
- 처음에는 설치 과정 : 필요한 개발 환경을 세팅
- 그 다음은 파이썬의 기본적인 개념들 : 자료형, 변수, 함수에 대해서 최대한 쉽게 알려드릴 건데요.
이것만 하고 나면 “프로그래밍 생각보다 별 거 아니네?” 하는 생각이 들 것입니다.
Topic 2. 프로그래밍 핵심 개념 in Python
이제부터 코딩이 왜 강력한 도구인지 알게 될 것입니다.
우리는 코딩을 왜 할까요? → 사람이 힘들어하는 것을 기계에게 대신 시키려고! [정밀 반복 계산, etc.]
프로그래밍의 세계는 넓고 깊지만, 결국 모두 몇 가지 핵심 개념에서 시작됩니다.
-'자료형'을 알면 데이터를 어떤 형태로 저장하고 활용하는지 이해할 수 있습니다.
-'추상화'를 알면 코드를 더 간결하고 근사하게 작성할 수 있습니다. 프로그래밍을 하나의 예술로 본다면,이게 바로 그 예술의 영역이라고 할 수 있죠.
-'제어문'을 알면 조건에 따라 동작을 나눌 수 있고, 반복적인 일을 처리할 수 있습니다. 컴퓨터를 반복적이고 어려운 일을 처리하는 똑똑한 비서로 활용할 수 있는 거죠.
이 토픽을 공부하고 나면, 세상에 많은 프로그램들이 대충 어떻게 돌아가는지 파악할 수 있습니다. 그리고 컴퓨터를 이용해서 어떤 문제를 해결하면 좋을지 아이디어가 마구 샘솟기 시작할 거라고 확신합니다.
Topic 3. 프로그래밍과 데이터 in Python
앞서 배운 정수형, 소수형, 문자열, 불린형 외에도 굉장히 많은 자료형이 있습니다. 그 중 가장 유용하게 사용할 수 있는 두 가지를 알려드리려고 합니다.
- 먼저 '리스트'라는 자료형이 있습니다.
리스트는 여러 값들을 하나로 묶어 주는 자료형입니다.
여러 값을 한꺼번에 다룰 수 있다는 장점이 있고, 여러 값을 원하는 순서대로 보관할 수 있다는 장점도 있습니다.
- 그 다음은 '사전'입니다. 사전도 리스트처럼 여러 값을 보관하는 자료형인데요.
순서대로 보관하는 것이 아니라, 마치 진짜 사전에서 단어를 찾듯이 값을 '검색'할 수 있다는 것이 특징입니다.
추가적으로 리스트, 사전, 문자열 등 파이썬 자료형의 비밀 몇 개를 알려드릴 건데요.
많은 분들이 잘 모르는 고급 정보니까 잘 배워 두시길 바랍니다!
Topic 4. Python 응용하기
프로그래밍 문법만 익히고 실제로 활용을 못하는 사람들이 대다수입니다. 원래 프로그래밍은 이론만 갖고 느는 게 아닌데 말이죠. 다양한 상황에 응용을 해 봐야 새로운 상황에 적용하는 능력이 생깁니다.
이 토픽에서는 파이썬을 이용해서 간단한 데이터 분석도 해 보고, 로또 시뮬레이션 프로그램이나 단어장 프로그램을 만들어 볼 것입니다. 그러면서 창의력과 응용력을 모두 기를 수 있습니다.
또한 그냥 기본 문법을 넘어서서, 파이썬을 더 확장성 있게 사용하기 시작할 건데요. 대표적으로는 새로운 모듈을 불러와서 쓰는 것과 유저에게 인풋을 받는 방법을 배워 볼 것입니다.
1. 추상화 Abstraction
⑴ 변수와 객체 [연결]

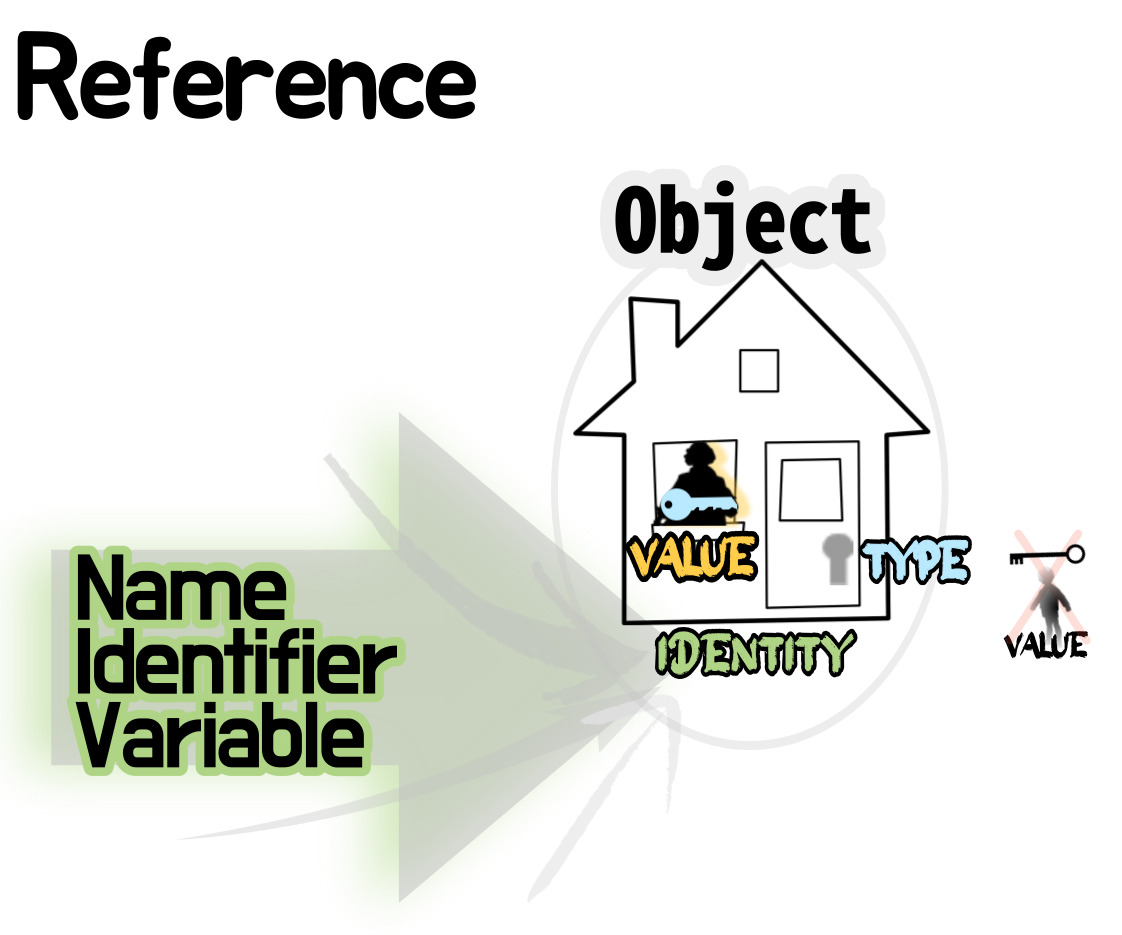
① 변수 → 객체:
[體: Entity독립체(포괄적) ≒ Data데이터(컴퓨터) ≒ Object객체(추상물) ] ⇆ [名: Identifier식별자≒Variable변수] ⇦ 👨🏻💻
[體]
└Entity독립체(포괄적) : 다른 것에 기대지 않고 홀로 서 있는 형체나 상태
└Data데이터(컴퓨터) : 프로그램 내 존재하는 표현 가능한 모든 독립체(entity)
└Object객체(추상물) [넓은의미] 파이썬이 Data데이터를 추상화 한 것 ∴파이썬의 모든 것이 객체
[좁은의미] Class가 정의한 type대로 만들어져 메모리주소를 할당받은 구체적 실체인 Instance
* instance의 일반적 의미인 '사례'도 특정 논리 틀에 찍혀나온 '썰'
[名]
└ Name이름 : Names refer to objects
└ Identifier식별자 : Object's name - Programmer can access object by using identifier
└ Variable변수 : [넓은의미] 객체를 가리키는 식별자 : Name ≒ Identifier ≒ Variable
↳ 모든 변수는 함수/클래스 객체를 가리킬 수 있음
∴ 변수를 다른 이름의 함수객체와 연결하는 것이 시스템적으로 구현가능하긴 함
[좁은의미] ⓐ가리키는 객체를 바꿀 수 있고, ⓑ함수, 클래스 객체가 아닌 객체를 가리키는 식별자
↳ 우리가 배운 일반적인 int, float, string, bool, list, tuple, dict, set, ··· 형 객체를 가리키는 식별자
이 의미로 변수를 인식하는 것이 더 명확하고 실전적인 듯 - 왜냐고? 소통때문에
Ex. 클래스 객체를 가리키는 변수가 있지만, 그걸 클래스 변수라고 하지 않음.
그거보다 클래스가 가지는 변수가 더 소통에 필요하니 걔를 클래스 변수라고 하는 식
변수는 비교하는 대상(객체/상수/변수클래스)에 따라, 다른 의미(연결성/변화가능성/역할)가 강조된다
* 객체도 변수도 넓은 의미를 알고는 있되, 생각은 좁은 의미로 적재적소에 하기
* 잡생각
🌸
내가 그의 이름을 불러주기 전에는
그는 다만
일련의 0과 1에 지나지 않았다.
내가 그의 식별자를 불러주었을 때
그는 나에게로 와서
객체가 되었다.
- 🌸 추상'화' 🌸 -
아 암튼, 컴퓨터와 소통하는 유저는 [名]을 사용함으로써 컴퓨터 속 [體]에 접근가능하다라는 말이 당연한 말이라구
② Object의 성분:
[Data → (추상≒추출) → Object객체]의 추출물 ⊃ Identity Type Value
└ [주소] Identity : 메모리 내 주소
└ [형] Type : 특정 객체들만이 가지는 특징으로 Type에 의해 객체의 동작 및 처리방식이 달라짐 ← 'Class'
└ [값] Value : ㄹㅇ 값 ← Type이 해당 객체가 담을 수 있는 값 결정
* 주소, 형, 값은 객체 생성 후 바꿀 수 없음
* 넓은 의미의 객체를 생각하면, 이 모든 추출물들도 객체다.
* object[體] ← class[틀]: Class → Type 정의하고, 그 형에 맞는 객체를 만듦(instance)
③ 성분파악&비교작업:
* id( ) 함수 → Return [ 입력받은 객체의 Identity를 '정수'로 표현한 값 ]
* < is > 이항연산자 → Return [ 두 객체의 Identity가 같은지를 비교한 후 True or False ]
* < == > 이항연산자 → Return [ 두 객체의 Value가 같은지를 비교한 후 True or False ]
* type( ) 함수 → Return [ 입력받은 객체의 Type/Class]
⑵ 변수와 상수 [변화-반의]
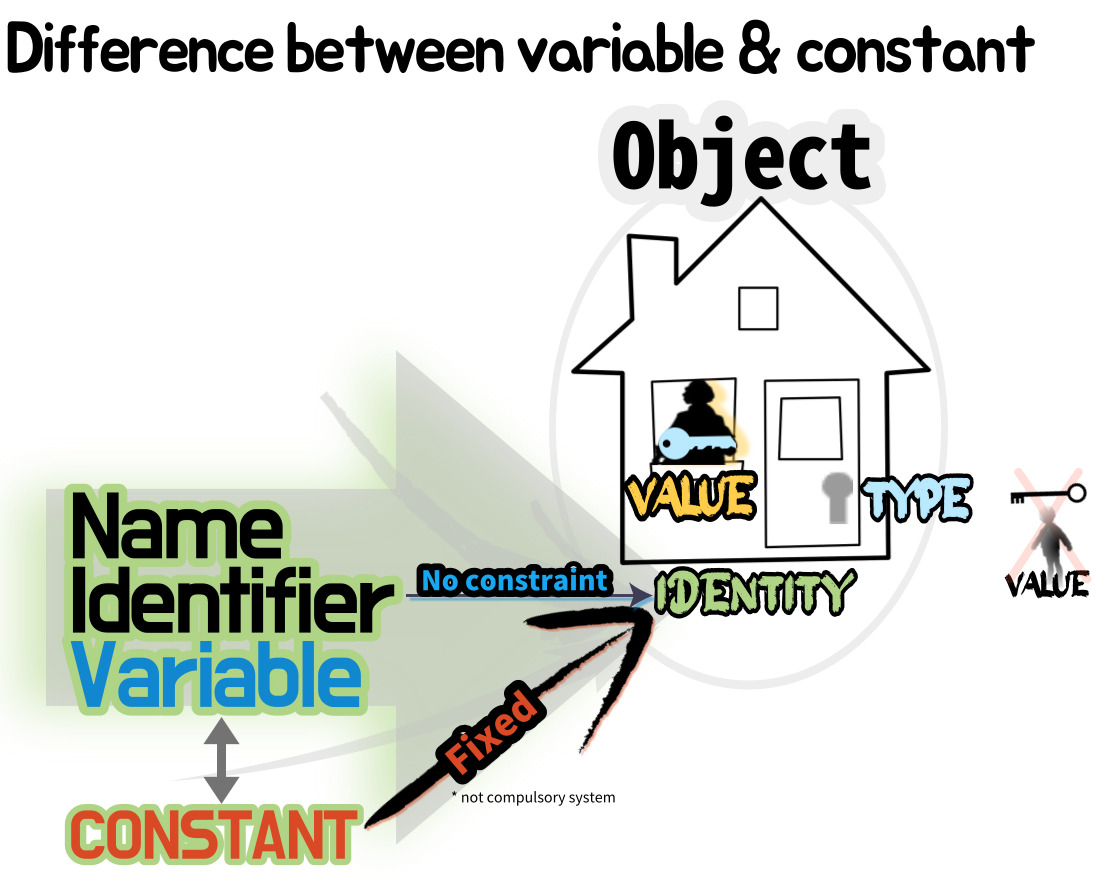
Identifier ∋ { 변수, 상수 }
- 변수variable → object : 가리키는 객체가 변할 수 있음
- 상수CONSTANT → object : 가리키는 객체가 변할 수 없음 & 전부 대문자
↳ 이 둘의 차이를 인터프리터는 모름 → 강제성 없는 프로그래머들만의 룰 ∴ 모르고 바꾸지 않도록 주의해야 함
* 일상에서 변수/상수는 반의어 관계인데, 파이썬 시스템 상에서는 변수 '중에서'
가리키는 객체를 바꿀 수 없도록 하고 싶을 때! 유저들끼리 대문자 표식으로써 정한 것이 상수
⑶ 변수와 함수&클래스 [📦역할-차원]
* Variable변수
[넓은의미] 객체를 가리키는 식별자 : Name ≒ Identifier ≒ Variable
↳ 모든 변수는 함수/클래스 객체를 가리킬 수 있음
∴ 변수를 다른 이름의 함수객체와 연결하는 것이 시스템적으로 구현가능하긴 함
[좁은의미] ⓐ가리키는 객체를 바꿀 수 있고, ⓑ함수, 클래스 객체가 아닌 객체를 가리키는 식별자
↳ 우리가 배운 일반적인 int, float, string, bool, list, tuple, dict, set, ··· 형 객체를 가리키는 식별자
이 의미로 변수를 인식하는 것이 더 명확하고 실전적인 듯 - 왜냐고? 소통때문에...?
① 영역의 차이:
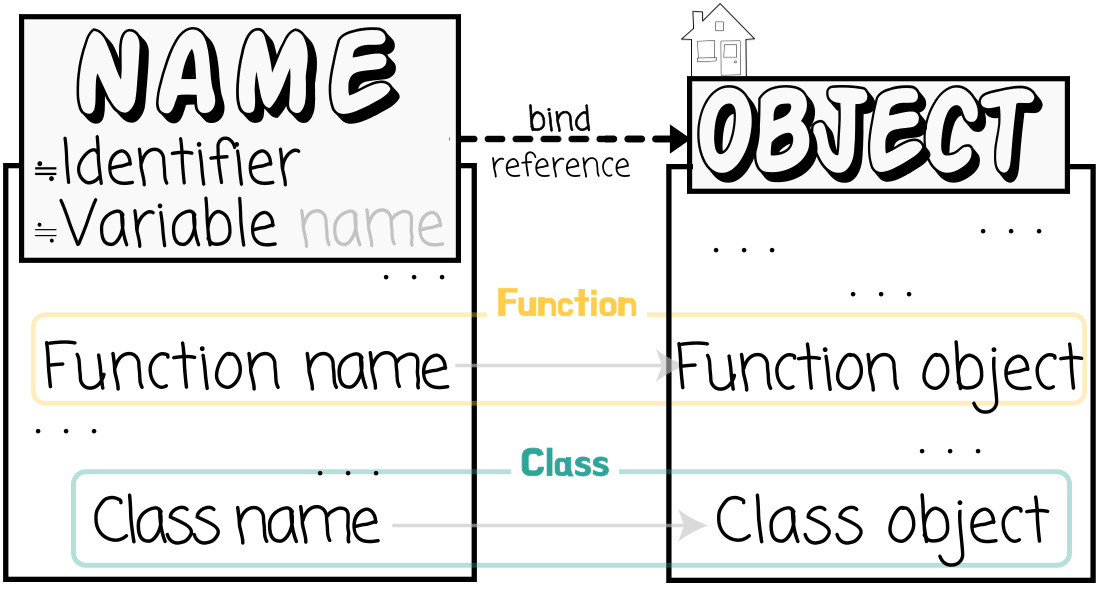
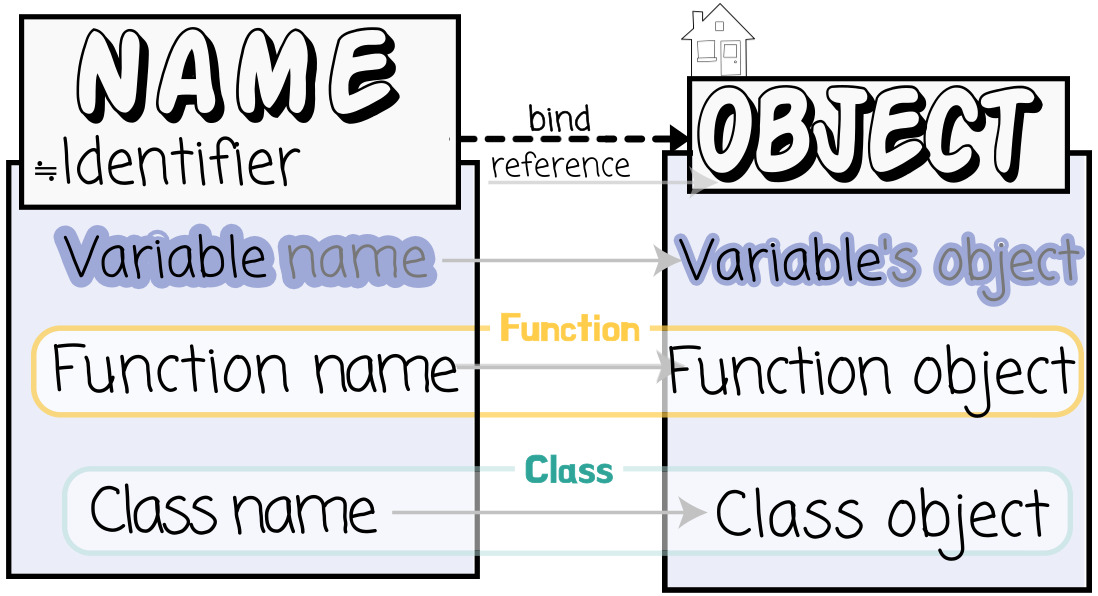
[Name] Variable변수 ⊃⊅ Function함수 Class클래스
↳ [名] 함수, 클래스는 넓은 의미의 변수이다.
[Object] Object객체 ⊅ Variable변수
⊃⊅ Function함수 Class클래스
↳ [體] 변수는 '변수→객체'관계가 명확하다.
↳ [名 & 體] 함수/클래스는 이름과 객체 둘 다를 함수/클래스라 부른다.
└ 추측이유? 해당 [함수名]이 해당 [함수객體]를 가리키는 것은 실전적으로 당연하니까(상수처럼),
함수/클래스는 역할이 중요하지, 이름과 객체를 구분짓는 건 안 중요한 것 같다.
변수는 해당 [변수]가 가리키는 [객체]가 '변'하는 것이 중요하지만!
② 역할의 차이:
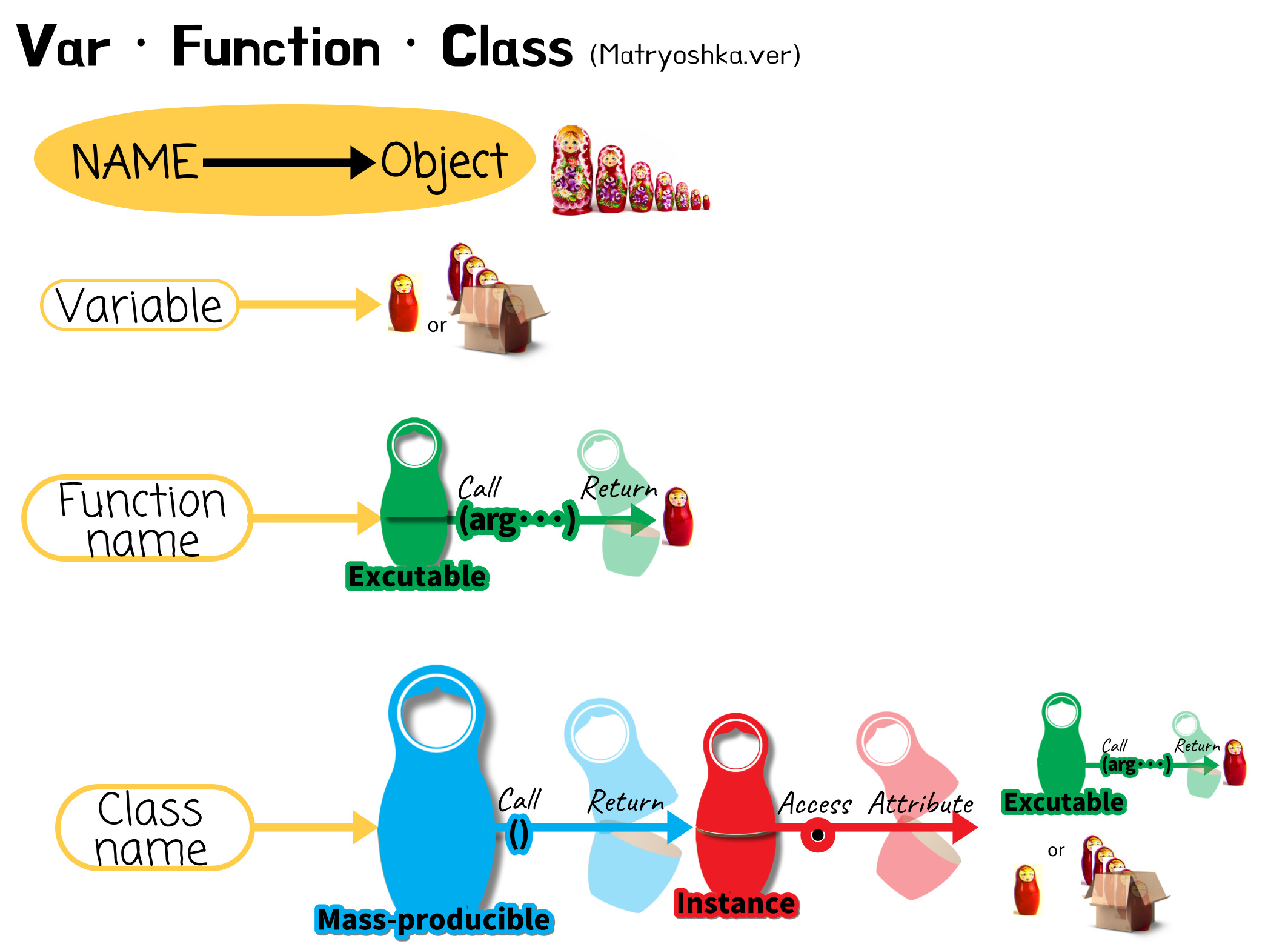
* [변] 가진 애
[함] → 명령을 가졌고 + () 실행하는 애
[클] → 제조법을 가졌고 + () 제조하고 + . 제조한 애도 뭘 가진 애
③ 정의&사용 방식의 차이:
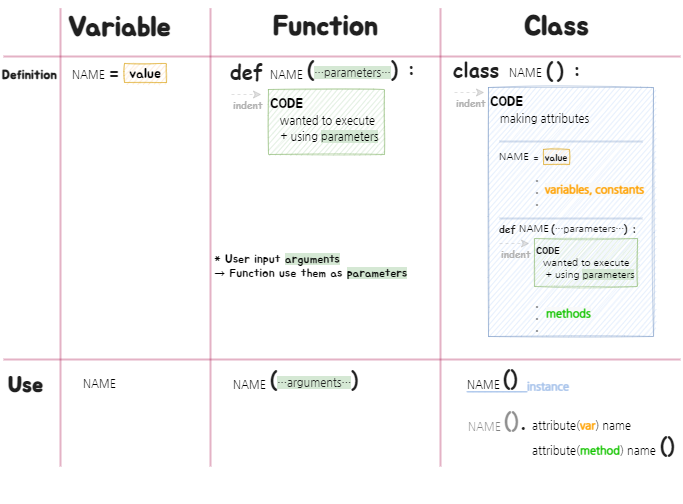
⑷ 변수의 사용범위 Scope
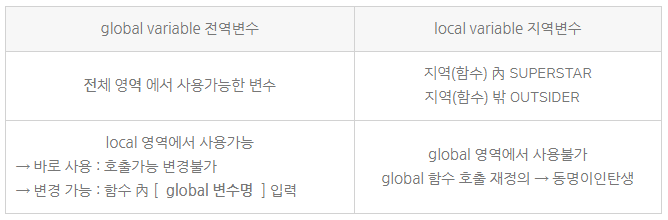
[Remark]
- Parameter ⊂ Local variable
- 전역변수[global] 함수영역(local) 사용가능하나 즉시변경X → global □
- 전역변수[global] & 지역변수[local] 동명이인이 존재할 수 있으나, 안 하는게 좋겠죠
⑸ Optional parameter
[예시] def name(a, b, c=1, d='a')
- Parameter : Local variable
- 必 Positional p. : 함수호출 시, 必 argument를 입력해야 함
- () Optional p. : 함수호출 시, argument를 입력 안하면 default값이 자동으로 파라미터에 할당됨
★ Optional은 무조건 Positional보다 뒤에 있어야 함 ★
~ 1. 추상화 Abstraction 끝 ~
# [변수] with ①객체, ②상수, ③함수클래스, ④Scope, ⑤Optional parameter
2. 자료형 Datatype

- Data type [python_docs][wiki]: 컴파일러나 인터프리터에게 알려주는 해당 object의 의미/특징
└ 이에 따라, 값을 저장하는 방식, 객체를 동작/처리(ex.연산, 형변환 등)하는 방식, 객체에 담을 수 있는 value가 달라진다.
└ Class가 type을 정의할 수 있다.
└ 자료형이 궁금한 경우 : type(■) → return <class 'name'>
└ 형변환 Conversion : 워너비자료형(■) → return NEW obj(같은value 다른type) 외운다기보다
└ Static & Dynamic typing : 언어분류기준 中 컴퓨터적 구조 명시必 or not
* 자료형을 잘 알면 전체 학습량의 50%을 습득한 셈이라고 하셨는데, 이제와서 보니 당연하다.
'객체, 객체의 동작/처리방식'이라는 이 두루뭉실한 영역이 해당 언어의 전부같이 느껴진다.
반대로, 자료형을 완벽하게 아는 건 그리 쉽지않다는 점에서 안도하게 된다.
컴파일러쪽으로 갈 게 아니라면? 완벽히 알기보다, 잘 사용할 수 있으면 되는 것 같다.
그래, 자료형 공부하다 머리가 빠개지는 건 정상이야!
⑴ 내장-자료형 분류

- 자료형 분류기준 : ① 독방/Container ②값 변경시, 변수→객체 도킹스타일
① Limited number of items → This criterion is related to 'Iterable' & 'Container'
└ 1obj(Container) ⊃ N item [Str List Tuple Dict Set ···]: 🎁 속 특정 item에 접근하기 위한 유일한 지표 필요
유일한 지표 : Int_index(Str List Tuple), Key_index(Dict), 값 그 자체(Set) | 그래서, set빼고 인덱싱 가능
Int/Key-index차이 : Int_index-순서대로, 자동으로 생성되는 정수형 지표 / Key_index-내맘대로 self생성
└ Iterable: 인자로 🎁를 받으면 스스로 하나씩 꺼내쓰는 상황(for, zip(), map(), ···)의 🎁
② [changing whole VS some items] x [Mutable VS Immutable]
└ Changing whole : [New Object in New memory address]도킹 ← variable
∴ [근본] variable의 도킹상태 💔'changed'
└ Changing some items:
1) Mutable : [New Object in New memory address]도킹 ← 前/後 기존 item들과 도킹
∴ [근본] variable의 도킹상태 ❤️'intact'
2) Immutable : Mutable의 방식 불가
∴ 함수/메소드/연산자를 통해 whole change방식으로 전환하여 값을 수정해야함
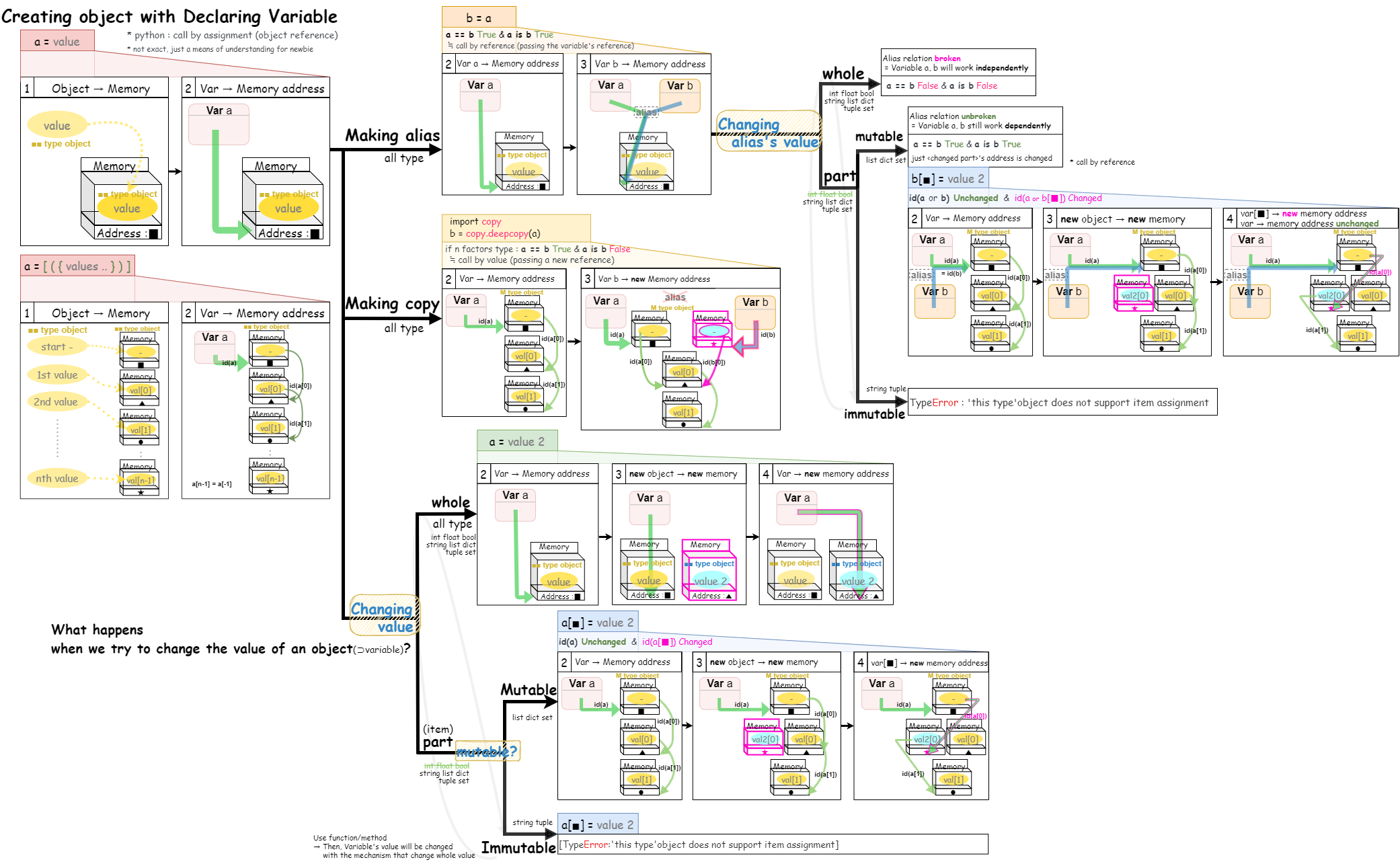
[Remark]
- 나는 '도킹'이라고 했는데, Name → obj를 binding이라고 하는 것 같음.
'도킹'이 뭔가 츼킹-츼킹 변신로봇같고 미래지향적이어서 더 쫚쫚 붙음............
- 자료형 분류 도식화를 두 번 했음. 배우는 과정 중에 / 코스 다 배우고서 재정리하는 맘으로 한번
그래서 내용이 막 겹치는데, 각자의 단순/세심 매력이 있는 것 같아서(?) 안 지우고 냅둠
⑵ 형변환
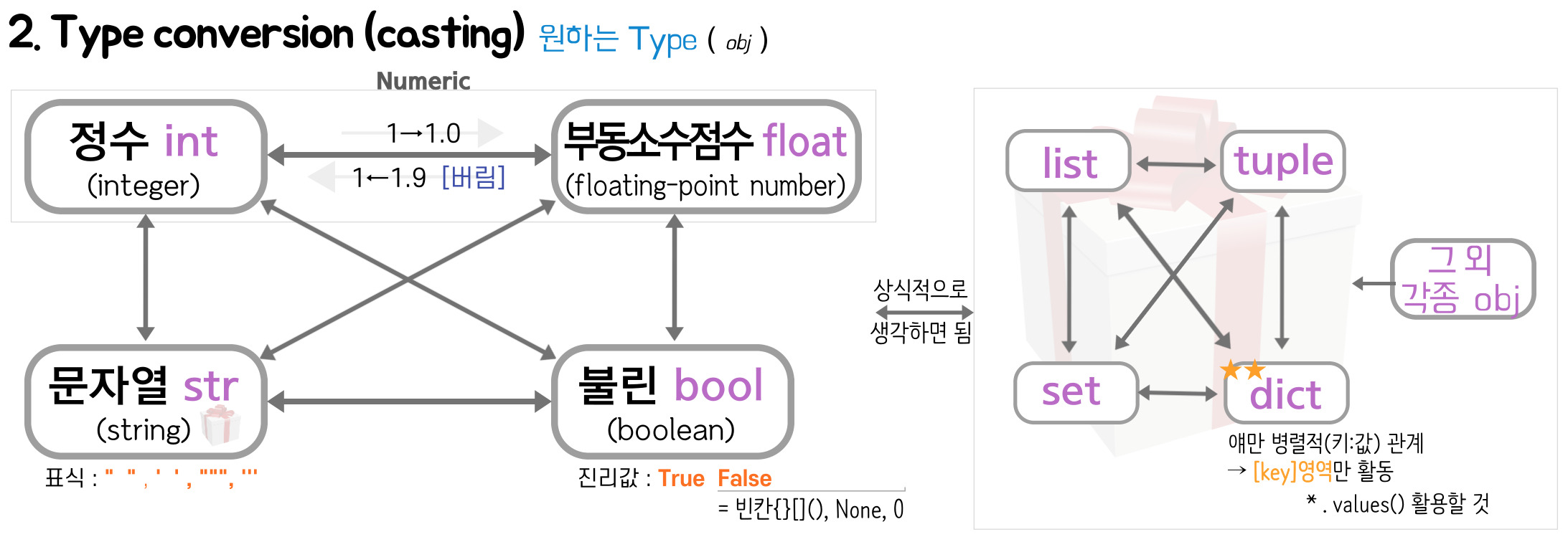
[Remark]
- float → int 반올림 아니고, 버림
- '1'→ int 가능 VS [1], {1} → int 불가
- '12.34' → int 직항 안 됨, 경유해야 함 : str"12.34" → float → int
- 인덱싱 → item형 / 슬라이싱 → 🎁type 형변환할 때 주의
- Container items 중복제거 → set형변환
- input()으로 받은 값은 무조건 str형이니까 필요하면 → 형변환
- dict는 형변환 할 때 key만
- 내장타입이 아닌 그냥 object도 형변환가능 → 따로 섹션(③)만들어서 설명
⑶ 그 외 자주보는 iterable
#range #zip #.items #file.txt
[공통점] 우리가 배운 내장타입은 아니지만, 배운 내장타입으로 형변환 가능
print(★)해선 원하는 값이 안 나옴 : ① for a in ★ 하거나, ② 형변환(str제외) 필요
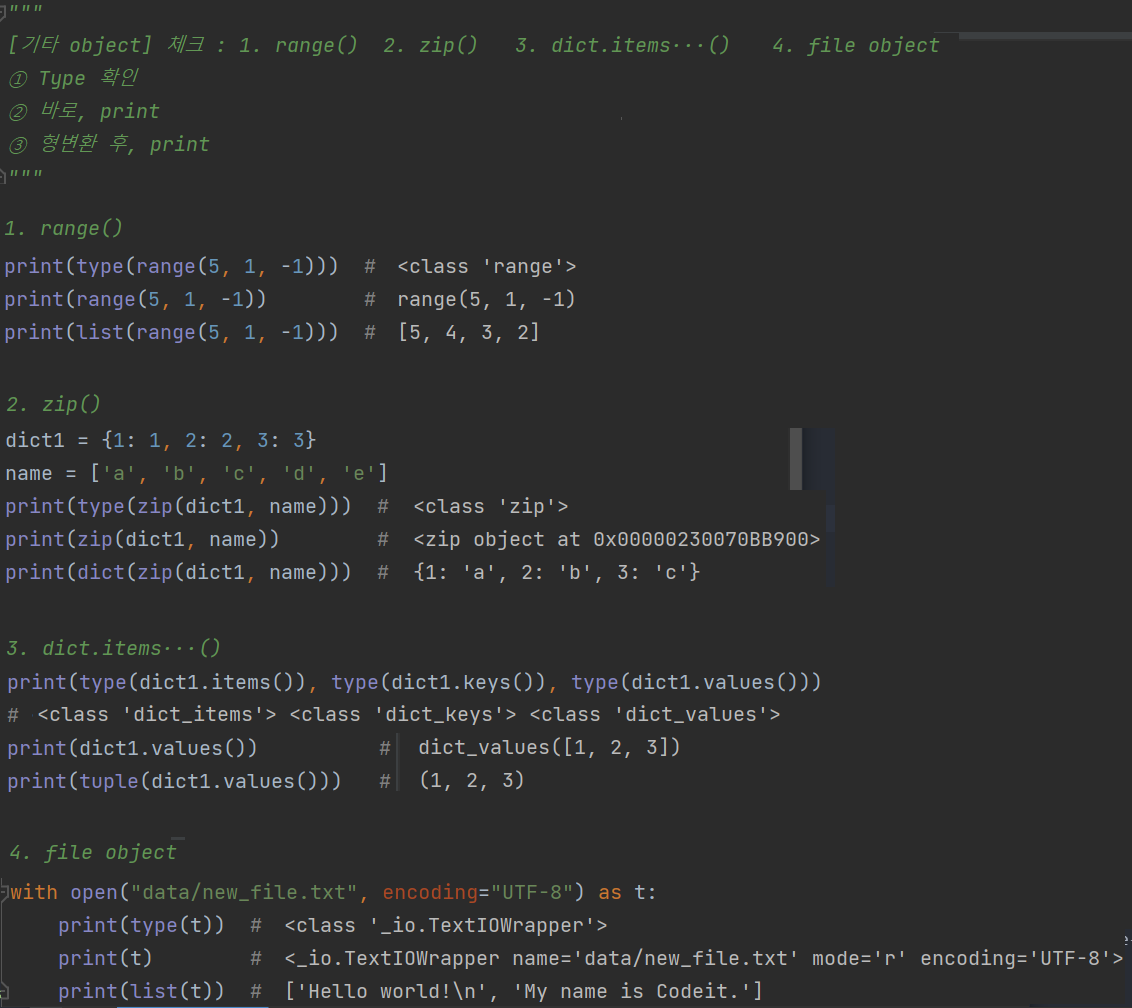
- ① range(시작a, 끝의 다음b, 공차d) : 첫 항a, 공차 d, b는 포함하지 않는 등차수열 객체
* 공차가 - 인 감소형 등차수열의 경우에도 단순하게 a출발 b닿지않는 끝, 헷갈려하지말기
∵ 딱딱한 공식처럼 b를 끝+1이라고 생각하면 헷갈림
- ② zip(iterable한 여러obj) :
'병렬적', item을 각각 객체별 하나씩 꺼내 tuple로 묶은 것을 item으로 가지는 객체
- ③ 사전객체.items/keys/values() :
dict객체에서 key/value만 모은 객체 혹은 그 둘{key: val} 모두를 tuple(key, val)로 묶어 모은 객체
* 2 arguments - zip(A, B) 한정 → dict 형변환 가능
- ④ txt파일객체 : txt파일의 한 줄을 반복의 단위로 하는 객체 → 추후, 입출력 정리에서 자세히 설명
~ 2. 자료형 Datatype 끝 ~
# [자료형] 中 내장형 분류: ① Container ② Mutable, 間 형변환, 中 자주보는 iterable형
3. String literals
⑴ Str. literal ⊂ literal ⊂ token
▶ 실재하는 token : 의미를 가지는 글자단위로써 file을 구성하는 조각 ∋ String literals
실재하는 Literals : Notations(표기) for constant values of some built-in types.
▶ 추상화를 거쳐 실체화 된 object ∋ String type object
┕ String literals → String type object's value ★
⑵ 기본 형태와 포멧팅
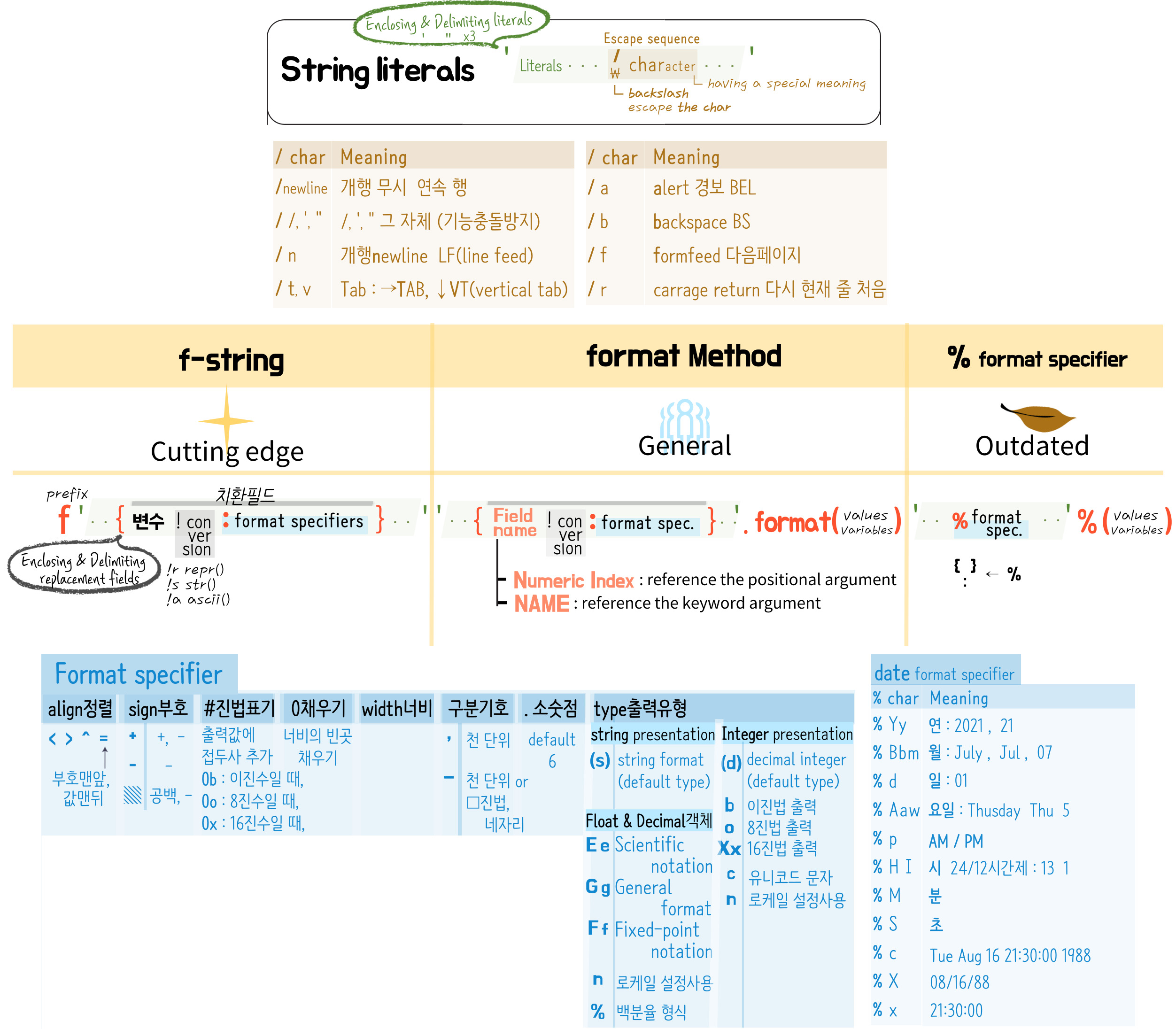
- 기본 형태 : 통째로 [ ', ", 삼중', 삼중" ]에 감싸짐 → 그 덩어리가 string/bytes literals란 의미
String/Bytes literals can be enclosed in matching [', ", triple quotes]. → must가 아니라 can ?
- \ (backslash) : '덩어리' 內에서, 특정 문자(character)를 문자 그대로가 아닌(escape)
→ 해당 문자가 가진 특별한 기능을 발동시켜줌
- 문자열포멧팅 : 여러가지 객체, 변수들이 첨가된 '문자열String'을 만드는 일
이 때, 객체나 변수들이 들어갈 위치 및 표현방식을 정할 수 있다.
① f '덩어리' 속, 변수를 담은 {치환필드}들 삽입 : {객체/위치/표현방식} 한큐처리
② '덩어리' 속, INDEX가 적힌 {치환필드}들 삽입.format(객체들) : 인덱스에 맞춰(객체들) → {위치/표현방식}
③ '덩어리' 속, %들 삽입 : 순서대로 (객체들) → % 위치/표현방식
~ 3. String literals 끝 ~
# [문자열 객체의 값 Value] ① quote 포장 ② 다른 value들을 literal로 쓰는 법
4. 구문Statement & 식Expression
문장은 ‘자신이 말하고자 하는 바’를 담은 최소완결체이다.
문장은 마음을 주고 받을 수 있는 소통의 단위이기때문에, 언어사용의 즐거움을 느낄 수 있는 시작점이다.
그래서, 언어는 문장단위로 배운다. 그 중요한 단어도 예문으로 익히는 것이 효과적이다.
파이썬도 언어다.
Statement는 문장, 컴퓨터에게 명령하고 컴퓨터가 Execution하는 소통단위이다.
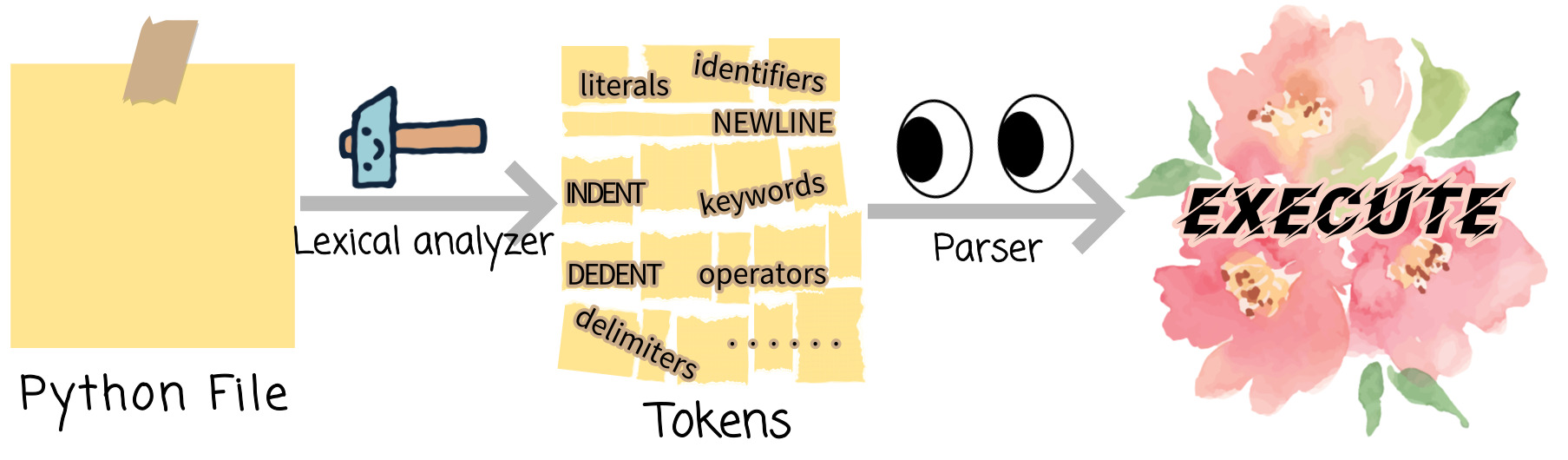
⑴ Token
[ 실제 프로그램이 읽히는 과정 ]
1. A file is broken into tokens by 'lexical analyzer'.
2. A Python program that become the stream of tokens is read by a 'parser'
* 실재하는 token : 의미를 가지는 글자단위로써 file을 구성하는 조각
[ Token 종류 ]
NEWLINE(논리적 줄 구분) INDENT & DEDENT(문장 간 수준 구분)
식별자(identifier) 키워드(keyword) 리터럴(literal) 연산자(operator) 구분자(delimiter)



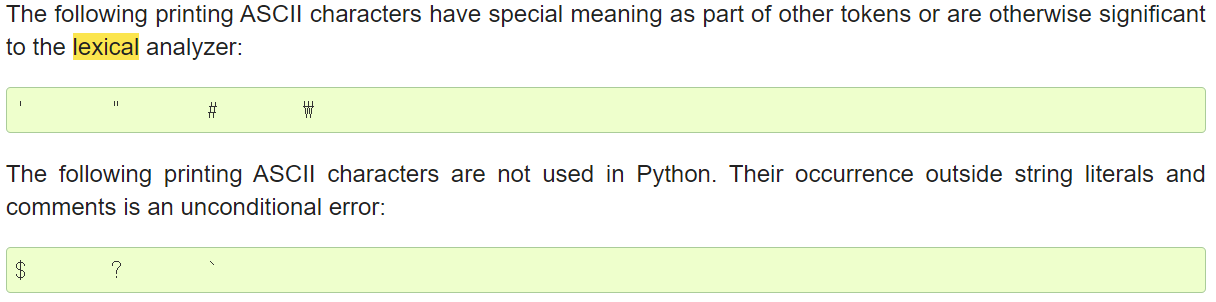
* 출처:Python.org/3/reference/lexical_analysis.html
⑵ Expression 정의 & 종류
- Expression : 식 → Obj
└ Expression return Object : 식은 객체를 뱉음
└ Statement에 사용할 수 있는 블럭 ← Expression
└ Expression 구성요소 : Atom ∋{ identifiers, literals, enclosures } & Operator
└ Identifiers → Bound object : 식 中 식별자는 자신과 연결된 객체를 뱉음
└ Literals → Object whose value is the literals : 식 中 리터럴은 자신을 value로 갖는 객체를 뱉음
└ Enclosures are forms enclosed in [{( ··· )}] → Object : 식별자나 리터럴들이 괄호로 포장된 형태
└ Operator → Object whose value is the result of operations using Atoms : 연산결과를 value로 갖는 객체를 뱉음
└ ∴ Operation ⊂ Expression
* Literals are notations for constant values of some built-in types.
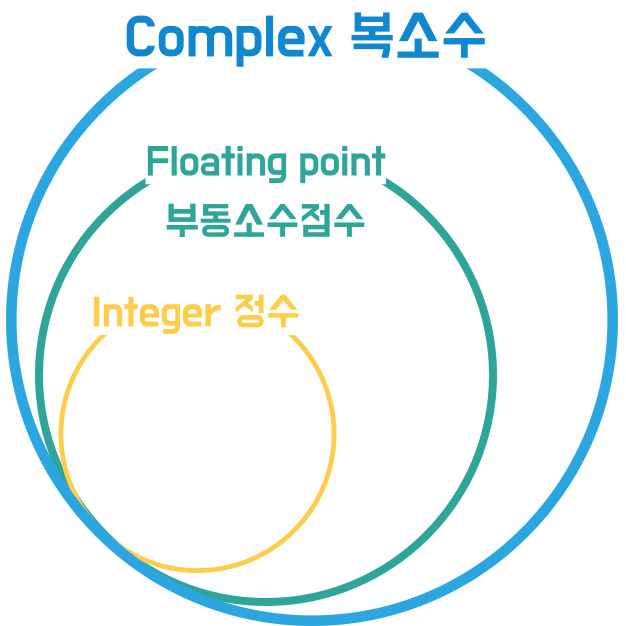
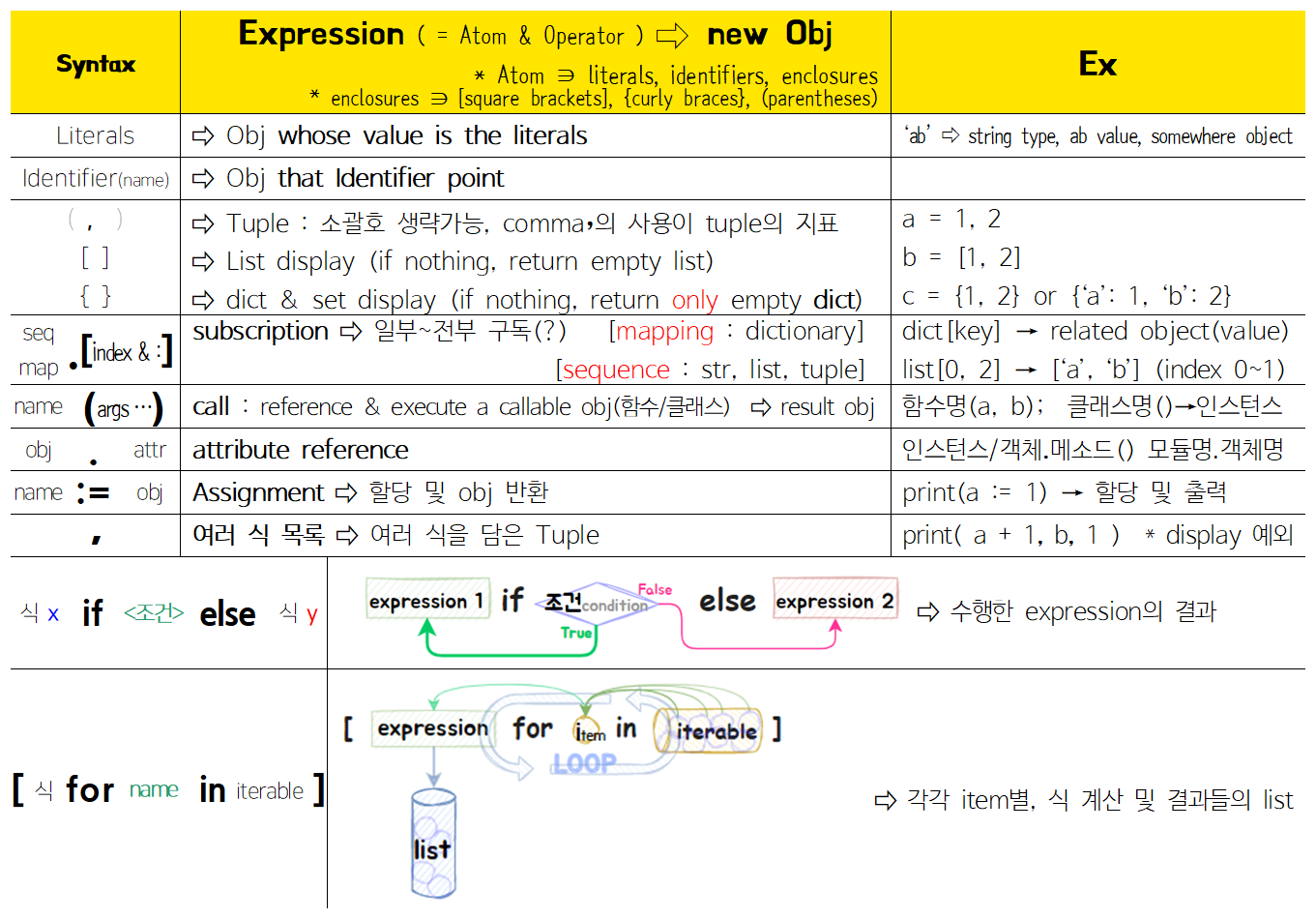
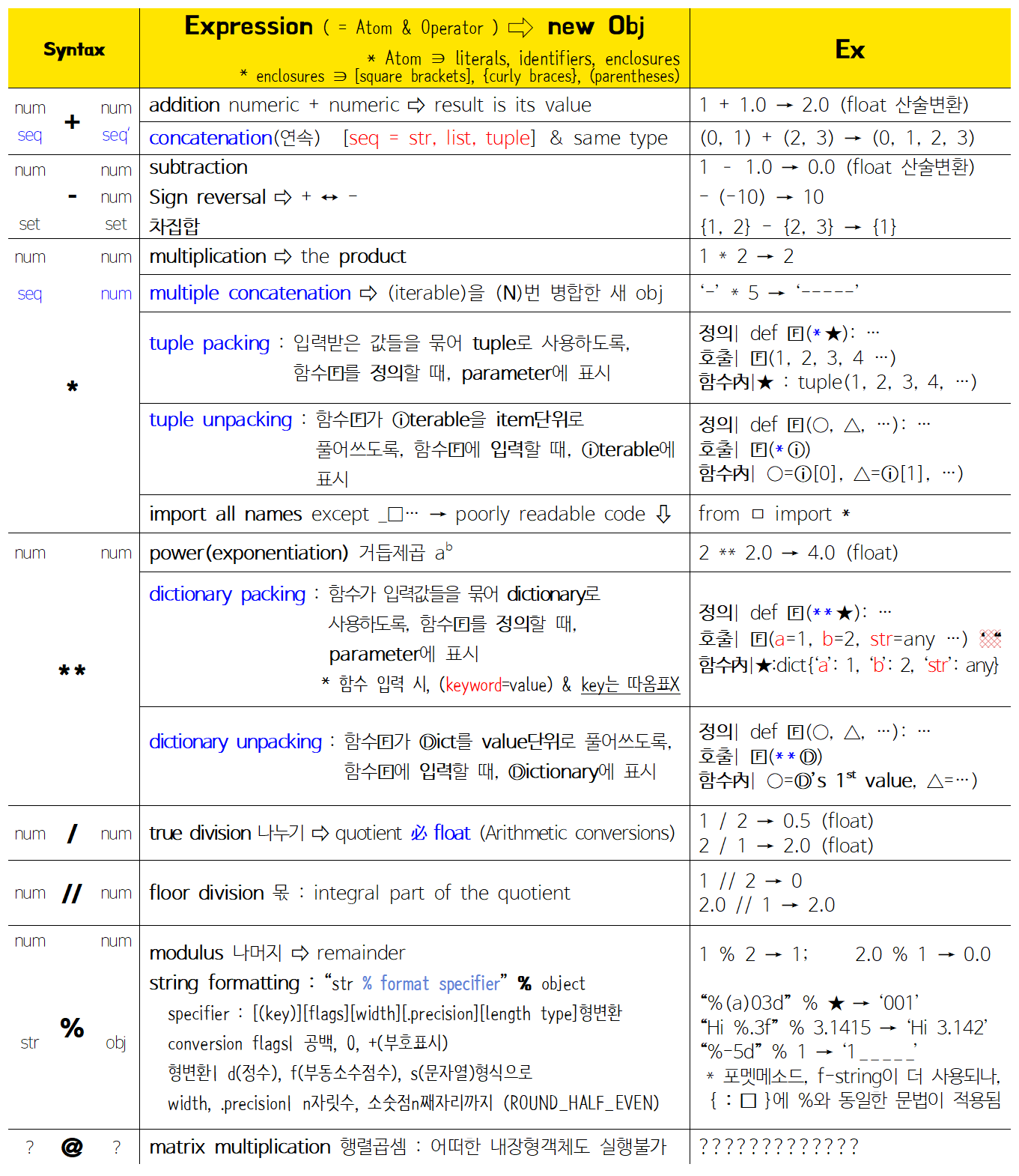
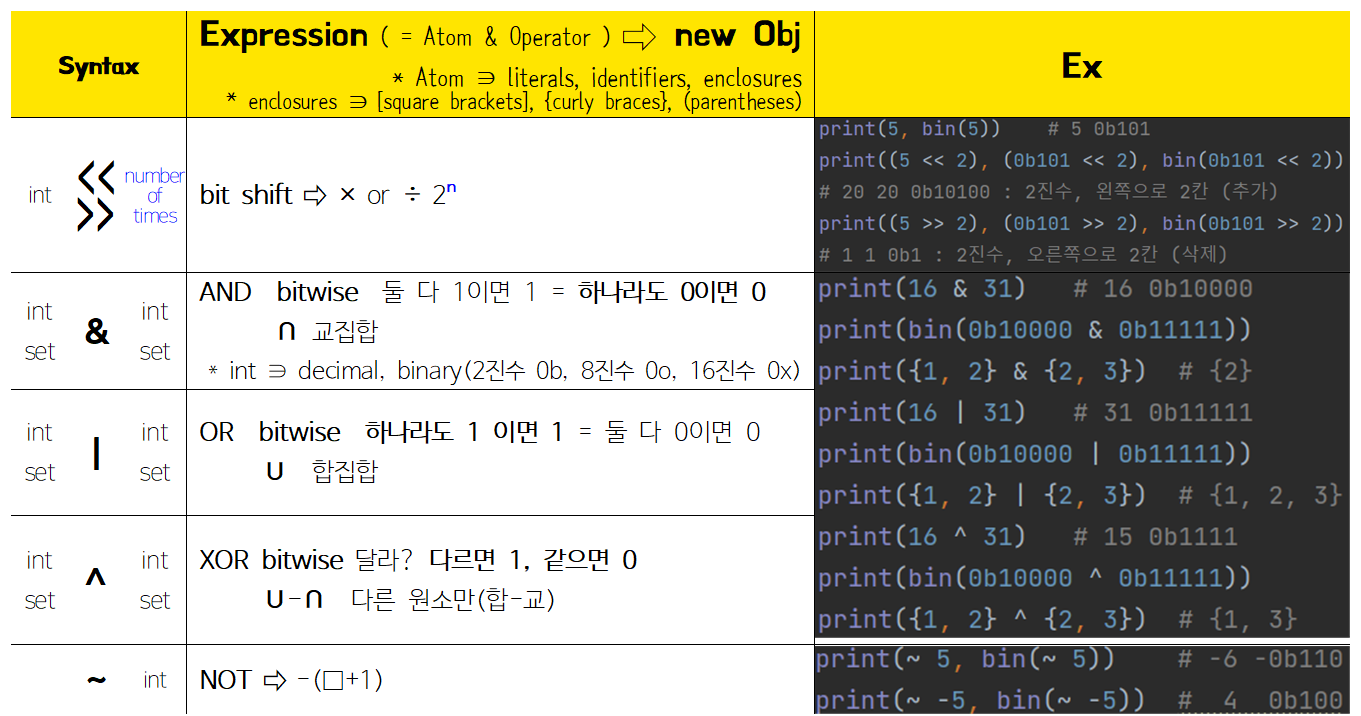
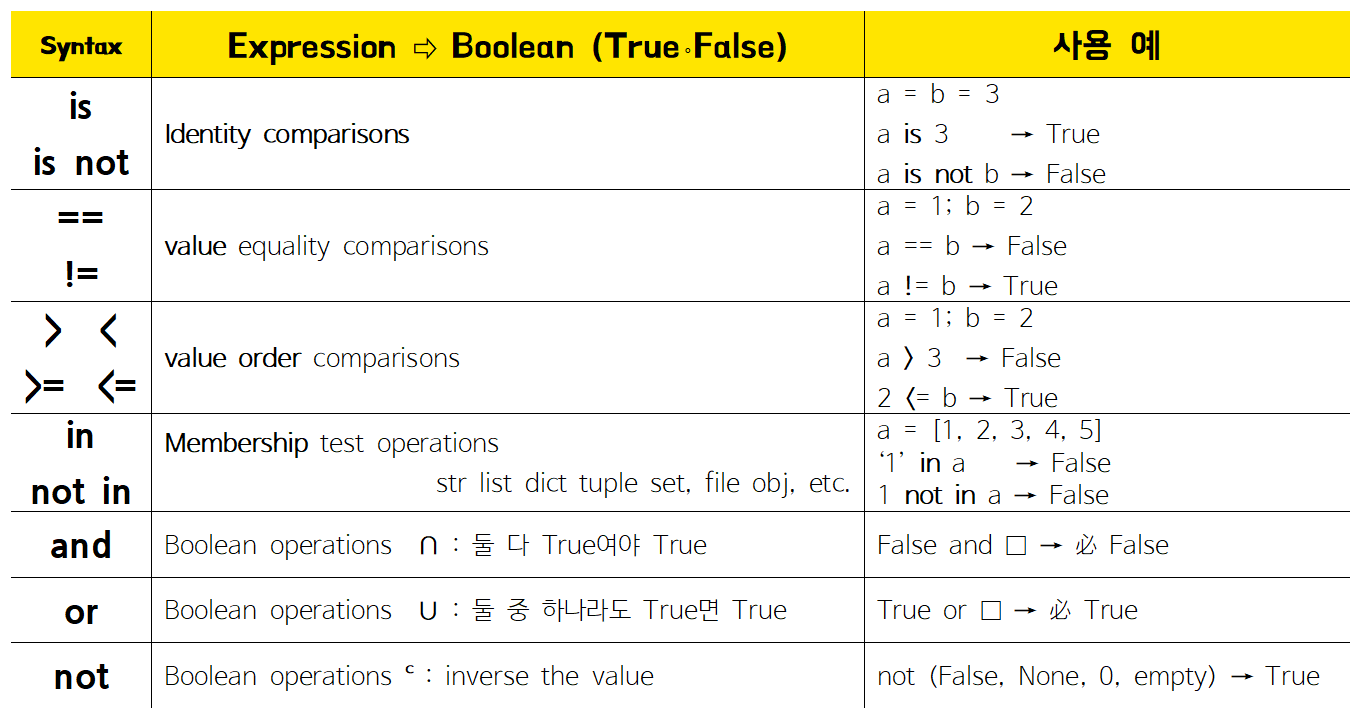
* 완전 모르겠어서 누락한 것 : 어웨이크, 일드, 람다
⑶ Statement 정의 & 종류
- Statement : 문
└ 평서문, 의문문, 청유문···등의 실제문장형식처럼, 대입문, 반복문, 조건문···등의 형식이 존재하는 문장
└ Statement ⊃ Simple(단순문:a single logical line) & Compound(복합문)
└ Compound Statement ∋ one or more 'clause'(절)
└ Clause 절 ∋ 'header머리 + suite덩어리'
└ Header [컨트롤타워] → Keyword로 시작해서 :로 끝남
└ Suite [실행부] → Header에 의해 제어되는 영역 : 같은 줄 or 개행 후, 동일한 들여쓰기 수준 정렬

* 정리는 단순/복합을 떠나, 종속적이지 않은 단위로 정리
* 인터넷 검색으로 찾았지만 읽어도 무슨 말인지도 모르겠고, 아직 안 배운 것도 재낌
① Assignment ↔ Delete
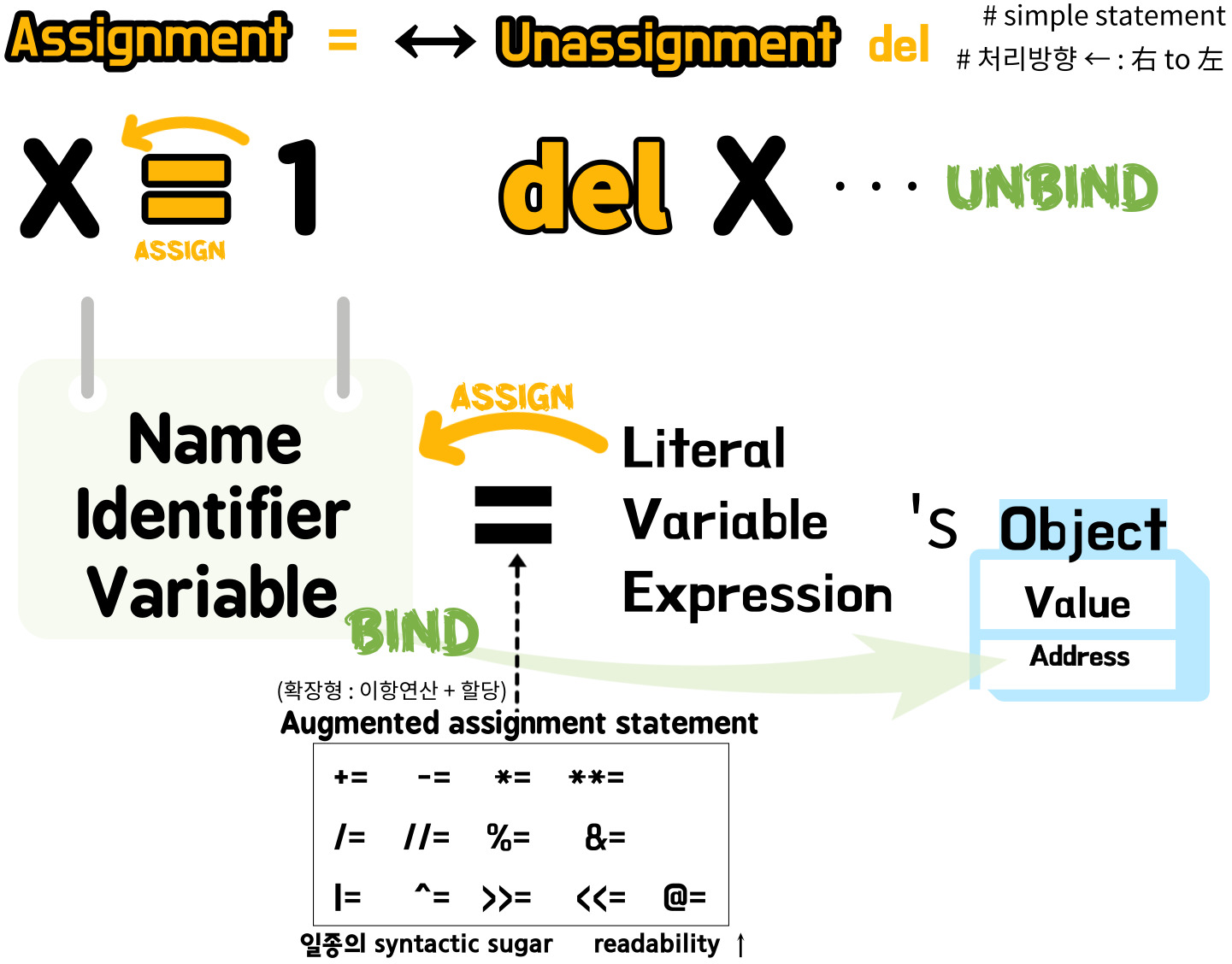
Assign 할당 - Name-Object Namespace BIND → =
Delete 제거 - Name-Object Namespace BIND 제거 → del
* 객체는 제거되지않음 → 어떤 것과도 bind 되어있지 않을 때, garbage collect될 뿐?
② Import module
▶ from □ import □ as □
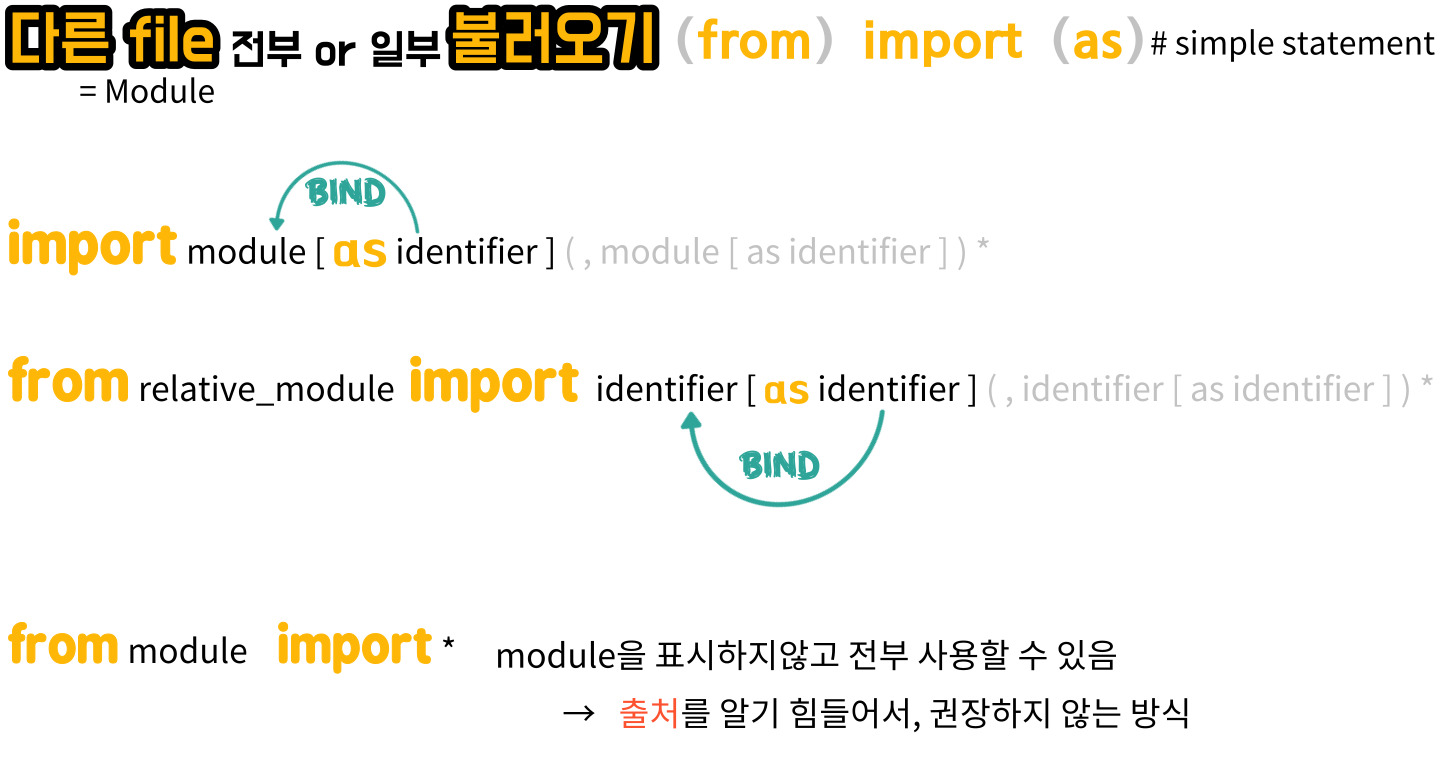
[ 자주 사용하는 모듈 ] math, decimal, random, datetime, os
▶ Standard library(표준라이브러리) : 파이썬 설치 시 딸려오는, 개발자들이 자주 쓰는 기능들을 담은 모듈의 모음
▶ [한글 설명서]
* Built-in : 함수/상수/타입/예외 → 우린 이미 Built-in 된 것들을 사용해왔음!
Module. math
Mathematical functions : This module provides access to the mathematical functions defined by the C standard.

▶ math.log(진수x [,밑])
└ 1 argument, Return 자연로그값 (= ln x )
└ 2 arguments, Return 로그값 (= log밑 진수)
└ 밑변환 log(x)/log(a) 연산을 하므로, 정확도가 떨어짐
▶ math.log2(진수x)
└ 1 argument, Return 밑이 2인 로그값
└ usually more accurate than log(x, 2)
▶ math.log10(진수x)
└ 1 argument, Return 상용로그값 (= log x)
└ usually more accurate than log(x, 10)
import math
# 함수 : log(진수[, 밑]) → return (float)지수
print(math.log(256, 4)) # 4.0
print(math.log2(256)/math.log2(4)) # 4.0 : log4(256) 밑변환 되네
print(math.log10(100)) # 2.0
print(math.log2(2**99)) # 99.0▶ math.sqrt(x)
└ 1 argument, Return the square root of x (=x의 양의 제곱근, 제곱근x)
import math
# 함수 : sqrt(x) → 제곱근x (float)
print(math.sqrt(1024)) # 32.0
print(type(math.sqrt(4))) # <class 'float'>▶ math.sin(x)
└ 1 argument, Return the sine of x radians
▶ math.cos(x)
└ 1 argument, Return the cosine of x radians
▶ math.tan(x)
└ 1 argument, Return the tangent of x radians
import math
# 함수 : sin/cos/tan(rad) → float
print(math.sin(0)) # 0.0
print(math.cos(math.pi)) # -1.0 : 코사인180도
print(math.tan(math.pi*(1/4))) # 0.9999999999999999 : 원래는 1인데▶ math.pi
└ Constant 파이(π)-The mathematical constant π = 3.141592…, to available precision.
▶ math.e
└ Constant 자연상수e-The mathematical constant e = 2.718281…, to available precision.
import math
# 상수 : 파이 ∏, 자연상수 e → (float)
print(math.e) # 2.718281828459045
print(math.pi) # 3.141592653589793
print(type(math.e), type(math.pi)) # <class 'float'> <class 'float'>
Module. random
Generate pseudo-random numbers - Almost all module functions depend on the basic function random(), which generates a random float uniformly in the semi-open range [0.0, 1.0)
[실수] Real-valued distributions
▶ random.random()
└ 0 argument, Return the next random floating point number [0.0, 1.0) = 0.0 ≤ N < 1.0
import random # 랜덤한 숫자를 생성하기 위한 다양한 함수들을 담은 module
# 1. random() → return 0.0 ≤ ■ < 1.0인 랜덤한 float 객체
print(type(random.random())) # <class 'float'>
print(random.random()) # 0.2623734691109664
print(f"{random.random():.2f}") # 0.71▶ random.uniform(a, b)
└ 2 argument, Return a random floating point number (a ≤ N ≤<b for a ≤ b, and b ≤ N ≤<a for b < a)
└ 끝 값을 범위에 포함시킬지의 여부는 a+(b-a)*random()방정식에 따른 부동소숫점반올림에 의해 결정됨
import random # 랜덤한 숫자를 생성하기 위한 다양한 함수들을 담은 module
# 2. uniform(a, b) → return a ≤ ■ ≤ b인 랜덤한 float 객체
print(type(random.uniform(-10, 10))) # <class 'float'>
print(random.uniform(-10, 10)) # 7.090006906596596
print(f"{random.uniform(-10, 10):.2f}") # -7.15[정수] for integers
▶ random.randint(a, b)
└ 2 arguments, Return a random integer N (a ≤ N ≤ b)
import random # 랜덤한 숫자를 생성하기 위한 다양한 함수들을 담은 module
# 3. randint(a, b) → return a ≤ ■ ≤ b인 랜덤한 int 객체
print(type(random.randint(-100, 100))) # <class 'int'>
print(random.randint(-100, 100)) # -91
print(random.randint(-100, 100)) # 17
Module. decimal
support for fast correctly-rounded decimal floating point arithmetic-float형보다 더 빠르고 정확한 십진수 부동소수점 산술을 지원함
[클래스-객체의 type을 정의하고(어트리뷰트:변수/상수/함수=메소드), 해당 클래스의 객체(인스턴스)를 생성할 수 있음]
▶ decimal.Decimal(■=str···)
└ 1 arguments, 값이 ■인 decimal.Decimal클래스의 인스턴스(객체)를 생성
└ 메소드 : 해당객체.quantize(exp, rounding=None, context=None)
└ Return quantize(정량화)시킨 새 Decimal 객체-rounds a number to a fixed exponent (원하는 소숫점자리까지 Round it)
└ 1st argument-exp : exponent(지수)-소수점의 위치 / Decimal형 객체입력-해당 객체의 소수점자리까지
└ (2nd argument-rounding) : round방식설정1순위 / rounding=■ & 없는 경우, context의 rounding값 / 예 : rounding=ROUND_UP
└ (3rd argument-context) : round방식설정2순위 / 없는 경우, current context의 설정 값
import decimal
# 반올림한 새로운 객체생성
print(decimal.getcontext().rounding) # ROUND_HALF_UP : 일반 반올림
a = decimal.Decimal('123.456789')
print(a.quantize(decimal.Decimal('1.'))) # 123 : current context 대로
print(a.quantize(decimal.Decimal('.1'), rounding='ROUND_UP')) # 123.5 : 올림
print(a.quantize(decimal.Decimal('.01'), rounding='ROUND_DOWN')) # 123.45 : 내림
print(a.quantize(decimal.Decimal('.001'))) # 123.457 : current context 대로▶ decimal.getcontext()
└ 역할 : 현재 설정 확인 및 변경 → 자세한 설명서
└ 0 arguments, Return 현재 상황이 담긴 객체-the current context for the active thread
└ print(■)→ Context(prec=28, rounding=ROUND_HALF_EVEN, Emin=-999999, Emax=999999, capitals=1, clamp=0, flags=[], traps=[InvalidOperation, DivisionByZero, Overflow])
└ 변경방법 : 해당객체.변경항목 = 변경값
└ 변경값 : rounding = 'ROUND_HALF_UP'반올림/'ROUND_UP'올림/'ROUND_DOWN'내림/'ROUND_HALF_EVEN'(.5 → 짝수), etc.
import decimal
a = decimal.getcontext() # Alias - 간편?
print(a) # 설정확인 : Context(prec=28, rounding=ROUND_HALF_EVEN, Emin= ···)
print(type(a.rounding)) # <class 'str'>
a.rounding = 'ROUND_HALF_UP' # 반올림으로 설정변경 & str형으로 입력해야함# round() VS Decimal형 객체.quantize()
print(round(13.5)) # 14 : ROUND_HALF_EVEN방식→올림 : 반올림인데,
print(round(13.4)) # 13 : ROUND_HALF_EVEN방식→버림 : 0.5인 경우는 (반)
print(round(12.5)) # 12 : ROUND_HALF_EVEN방식→버림★: 결과가 짝수이도록 올/내리는 방식
import decimal
a = decimal.Decimal('13.5') # Decimal클래스의 객체(instance)생성
b = decimal.Decimal('12.5') # 인수는 int/float/str/tuple형 다 되는데, str 추천
print(type(a)) # <class 'decimal.Decimal'>
print(decimal.getcontext().rounding) # 현 설정 : ROUND_HALF_EVEN
c = a.quantize(decimal.Decimal('1.')) # 현 설정대로 rounding한 새로운 객체
d = b.quantize(decimal.Decimal('1.')) # 현 설정대로 rounding한 새로운 객체
print(c) # 14 ← 13.5
print(d) # 12 ← 12.5 ★
decimal.getcontext().rounding = 'ROUND_HALF_UP' # 설정변경 : 일반 반올림
c = a.quantize(c) # c의 소숫점자리대로 + 현 설정대로 rounding한 새로운 객체
d = b.quantize(d) # d의 소숫점자리대로 + 현 설정대로 rounding한 새로운 객체
print(c) # 14 ← 13.5
print(d) # 13 ← 12.5 ★Module. os
This module provides a portable way(이식가능한 방법) of using operating system dependent functionality(운영체제에 종속된 기능).
▶ os.getlogin()
└ Return (str) 현 프로세스의 제어 터미널에 로그인한 사용자 '이름'-the name of the user logged in on the controlling terminal of the process.
▶ os.getcwd()
└ Return (str) 현 작업 디렉토리-a string representing the current working directory.
import os # 운영체제를 조작하기위한 모듈
# getlogin() → 현재 로그인 되어있는 계정
print(os.getlogin()) # 계정명 출력
# 현재 파일이 있는 경로 출력
print(os.getcwd()) # C:\ 블라블라 출력
print(type(os.getlogin()), type(os.getcwd())) # <class 'str'> <class 'str'>
Module. datetime
날짜와 시간을 다룰 수 있는 클래스 & 산술 - This module supplies classes for manipulating dates and times.
+ Aware objects-can locate itself relative to others, represent a specific moment in time without interpretation.
+ Naive objects-up to the program, easy to understand and work with.
[클래스-객체의 type을 정의하고(어트리뷰트:변수/상수/함수=메소드), 해당 클래스의 객체(인스턴스)를 생성할 수 있음]
[* Object of these type is immutable]
▶ datetime.date(year, month, day : int형)
└ 날짜(연, 월, 일)만 다루는 객체를 정의하는 클래스
└ 3 arguments, 해당 값들을 attribute로 가진 datetime.date클래스의 인스턴스(객체) 생성
└ 클래스 메소드 : date.today()
└ Return 현재 날짜값들을 attribute로 가진 datetime.date클래스의 인스턴스(객체)
└ 인스턴스 메소드 : 특정객체.replace(year=self.year, month=self.month, day=self.day)
└ Return 해당 객체의 특정 attribute를 바꾼 새로운 datetime.date클래스의 인스턴스(객체)
└ 인스턴스 메소드 : 특정객체.strftime(format="···")
└ Return 해당 객체의 날짜관련attribute를 명시한 포맷에 맞춘 문자열(string from time)
▶ datetime.time(hour=0, minute=0, second=0, microsecond=0, tzinfo=None, *, fold=0)
└ 시간(시, 분, 초, ···)만 다루는 객체를 정의하는 클래스
└ All optional arguments, 해당 값들을 attribute로 가진 datetime.time클래스의 인스턴스(객체) 생성
└ 인스턴스 메소드 : 특정객체.replace(hour=self.hour, minute=self.minute, second=self.sec···)
└ Return 해당 객체의 특정 attribute를 바꾼 새로운 datetime.time클래스의 인스턴스(객체)
└ 인스턴스 메소드 : 특정객체.strftime(format="···")
└ Return 해당 객체의 시간관련attribute를 명시한 포맷에 맞춘 문자열(string from time)
▶ datetime.datetime(year, month, day, hour=0, minute=0, second=0, microsecond=0, tzinfo=None, *, fold=0)
└ 날짜와 시간을 모두를 다루는 객체를 정의하는 클래스
└ 3↑ arguments, 해당 값들을 attribute로 가진 datetime.datetime클래스의 인스턴스(객체)를 생성
└ 클래스 메소드 : datetime.now(tz=None)
└ Return 현재 날짜와 시간을 attribute로 가진 datetime.datetime클래스의 인스턴스(객체)
└ 클래스 메소드 : datetime.combine(date, time, tzinfo=self.tzinfo)
└ Return 입력한 date객체와 time객체의 각 attribute값을 결합한 datetime.datetime클래스의 인스턴스(객체)
└ 인스턴스 메소드 : 특정객체.strftime(format="···")
└ Return 해당 객체의 날짜시간관련attribute를 명시한 포맷에 맞춘 문자열(string from time)
└ * 포맷코드 : 연%Y,y 월%B,b,m 일%d 요일%A,a,w 오전오후%p 시%H(24h),I(12h) 분%M 초%S
└ Appropriate representation : %c → Tue Aug 16 21:30:00 1988 %x → 08/16/88 %X→21:30:00
└ * 메소드 사용하지않고, 문자열포멧팅 "문자와 포멧코드".format(시간관련 인스턴스)로 하는 것도 괜찮은데...
import datetime
now = datetime.datetime.now() # 현재 연월일시분초를 담은 datetime.datetime 인스턴스
print("Today is " + now.strftime("%A(%B %dth)")) # Today is Thursday(June 10th)
print("Today is {0:%A}({0:%B} {0:%d}th)".format(now)) # Today is Thursday(June 10th)
print(now.strftime("%c")) # Thu Jun 10 15:40:40 2021 = 요일 월 일 시:분:초 연
print(now.strftime("%x")) # 06/10/21 = 월/일/연
print(now.strftime("%X")) # 15:40:40 = 시:분:초└ 지원하는 연산 : datetime = datetime ± timedelta
└ 지원하는 연산 : timedelta = datetime - datetime
▶ datetime.timedelta(days=0, seconds=0, microseconds=0, milliseconds=0, minutes=0, hours=0, weeks=0:int, float, +, -)
└ 두 객체(date, time, datetime클래스)의 차이기간을 의미하는 객체(인스턴스)를 다루는 클래스
└ All optional arguments, 해당 값들을 attribute로 가진 datetime.timedelta클래스의 인스턴스(객체) 생성
└ 지원하는 연산 : datetime = datetime ± timedelta
└ 지원하는 연산 : timedelta = datetime - datetime
import datetime
# .datetime(연, 월, 일, 시, 분, 초)
print(type(datetime.datetime(2021, 5, 28))) # <class 'datetime.datetime'>
print(datetime.datetime(2021, 5, 28)) # 2021-05-28 00:00:00
print(datetime.datetime(2021, 5, 28, 15, 28, 9)) # 2021-05-28 15:28:09
# 객체의 attribute :
today = datetime.datetime.now()
print(type(today.year)) # <class 'int'>
print(today.year) # 2021
print(type(today.microsecond)) # <class 'int'>
print(today.microsecond) # 543286
# 객체의 method : .datetime.now() → return 현재
print(type(datetime.datetime.now())) # <class 'datetime.datetime'>
print(datetime.datetime.now()) # 2021-05-28 15:29:08.860917 : 시간단위
first_delta = datetime.timedelta(
days=48,
seconds=16,
microseconds=10,
milliseconds=19000,
minutes=1,
hours=2,
weeks=3
)
second_delta = datetime.timedelta(weeks=1, hours=3, minutes=4, seconds=5)
# datetime객체끼리 빼기 → 시간차를 나타내는 timedelta객체
dday = datetime.datetime(2021, 6, 1)
today = datetime.datetime.now()
print(type(dday - today)) # class 'datetime.timedelta' 시간차
print(dday - today) # 3 days, 8:28:28.426436
# datetime객체+-timedelta객체 → datetime객체
print(datetime.datetime.now()) # 2021-05-28 15:44:54.264421
print(type(datetime.datetime.now() + second_delta)) # class 'datetime.datetime'
# 설정하지 않은 항목은, default to 0
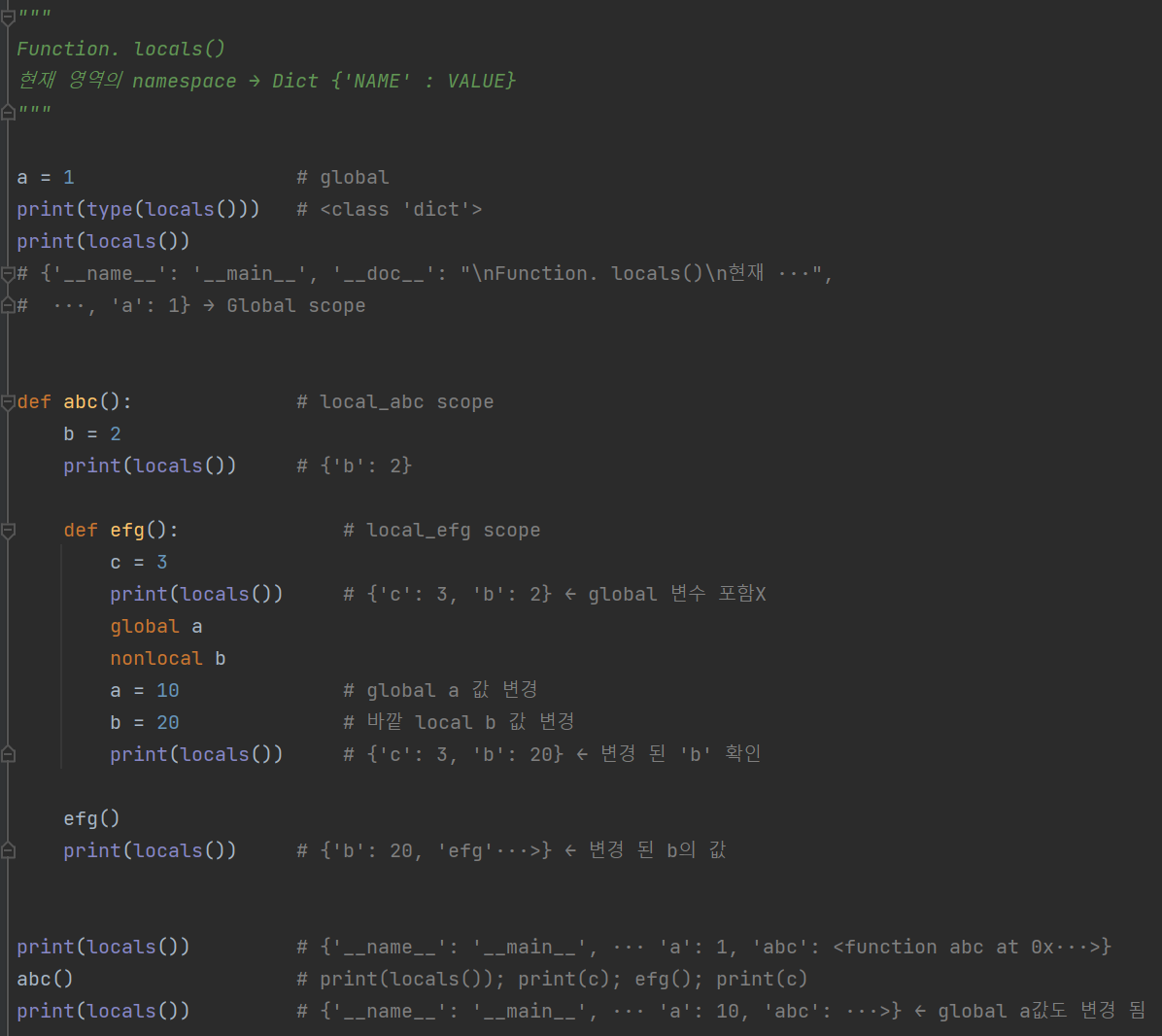
③ 다른 영역의 변수 사용
▶ 전역변수 : global □
▶ 둘러싼 지역의 변수 : nonlocal □
▶ 변수목록(Namespace) : locals()

④ Pass
▶ pass
아무 일도 일어나지 않음 NULL → SUITE를 빈칸으로 두고 싶을 때, 사용
⑤ 함수/클래스 정의

▶ def 함수명(parameters):SUITE
▶ class 클래스명():SUITE
⑥ 조건부실행
▶ if:
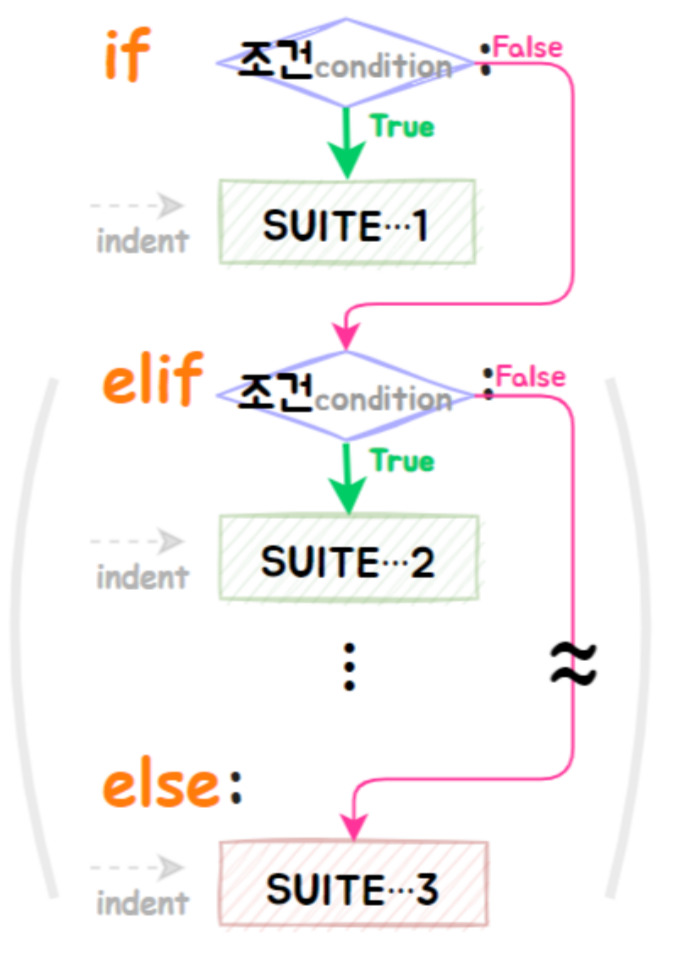
<조건식ⓒ> 순차적 연산 : <조건식ⓒ<의 결과값이 True인 경우 → 해당 SUITE 실행 & 구문종료
if <ⓒ> : SUITE
elif <ⓒ> : SUITE ··· 생략가능 & 여러 개 OK
else : SUITE ··· 생략가능 & only one
⑥ 반복
▶ while , for:
+ continue : 현 Loop cycle 즉각 중단 & 다음 Loop cycle 실행
+ break : 현 Loop cycle 즉각 중단 & 탈출
* finally절이 있는 경우, loop 탈출 전 실행 함
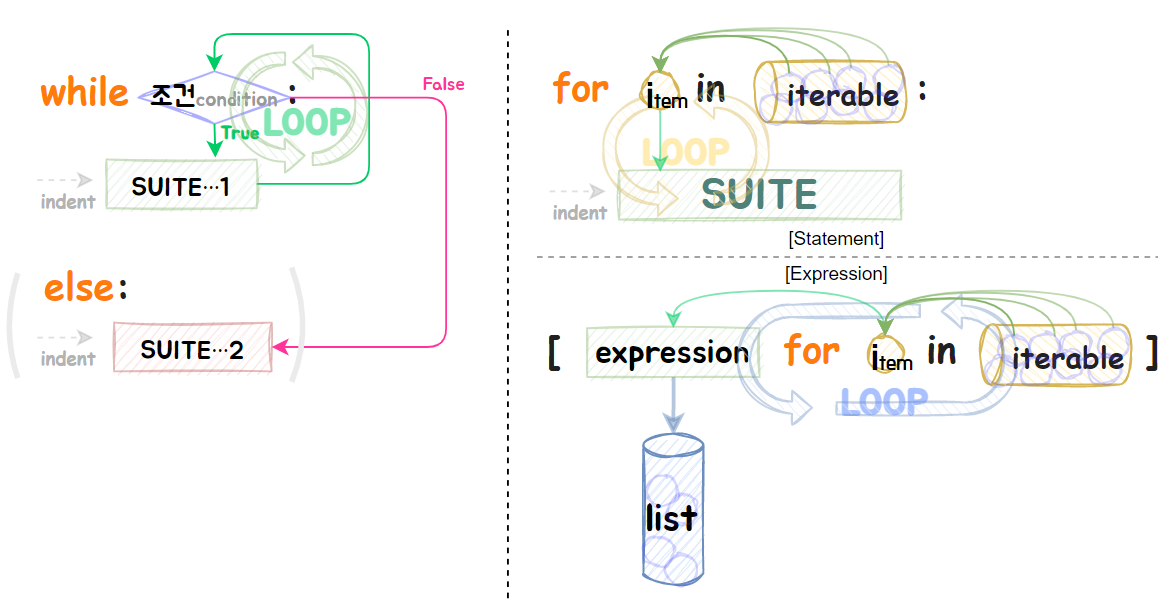
while <ⓒ> : SUITE ··· <조건ⓒ>가 True인 동안, SUITE 반복
else : SUITE ··· (생략가능: <조건ⓒ>가 False일 때, SUITE실행) & Loop out
for □ in 🎁 : ··· 🎁 속 item 하나하나씩 꺼내서 → □ 담기 & SUITE 실행
else : SUITE ··· (생략가능: 모든 🎁의 item 소진 시, SUITE실행) & Loop out
⑦ 예외처리
▶ try : - except ⓐ as □: else :- finally :
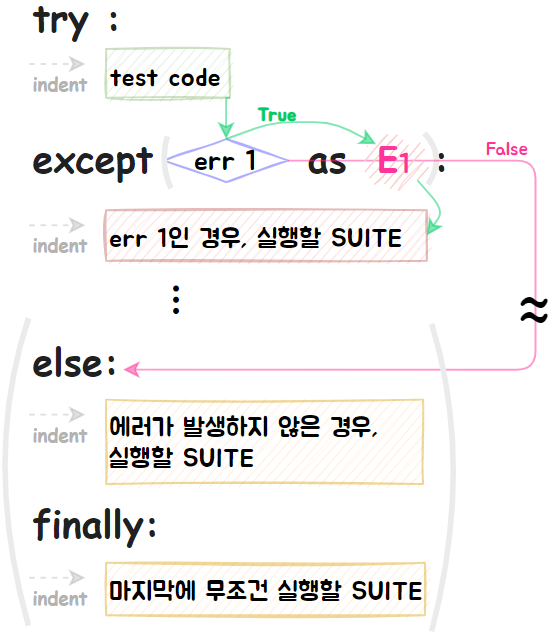
try : SUITE ··· SUITE 실행 → Err발생?-① or 정상?-②
except ⓐ as □: SUITE ··· ① try절 SUITE가 ⓐ라는 에러를 일으키는 경우, SUITE 실행 + 여러 절 OK
else : ··· ② try절 SUITE가 에러를 일으키지 않는 경우, SUITE 실행 (생략가능)
finally : SUITE ··· try절이 에러를 일으켰든 말든 마지막으로 무조건 실행 (생략가능)
⑧ 컨텍스트 자동종료
with EXPRESSION as TARGET:
SUITE↓
with open('폴더명/파일명', 'r=읽기 or w=쓰기', 'encoding=인코딩방식') as 결과물명:
SUITE[기존-불편] open(□)으로 파일을 여는 경우, △.close()로 수동으로 닫아줘야 함
[해결-편함] with open(□)··· :SUITE - with문이 끝날 때, 자동으로 닫음
⑷ 식 VS 구문
Expression vs Statement
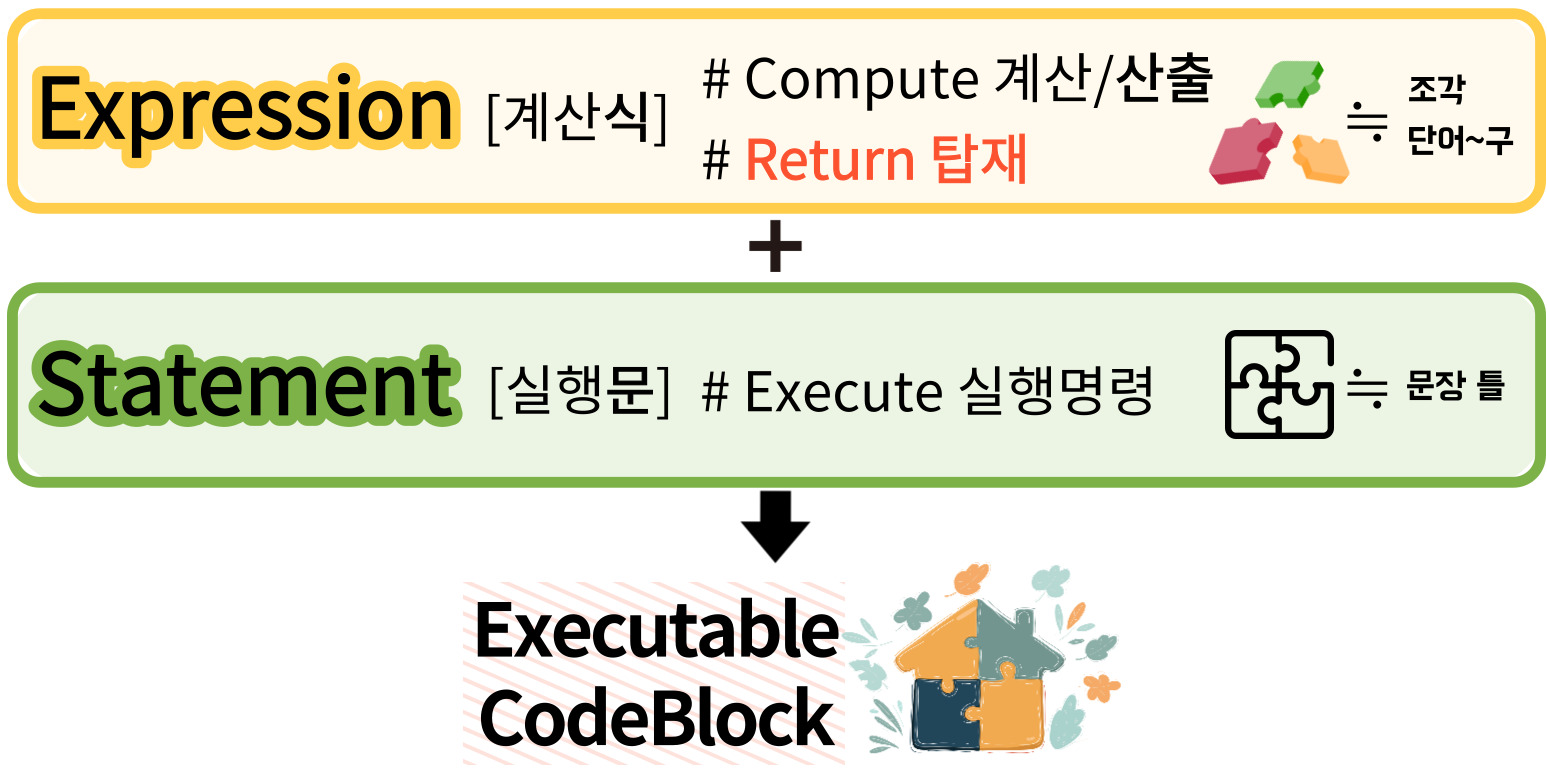
[식:준비물] Expression #Auto Return object #퍼즐조각
[문:실행계획] Statement #No return responsibility #퍼즐판
KEY POINT → Is it automatically return a value?
🟢 Expression → so 'expression' need follow-up executable procedure.
→ 식은 자동으로 뭔가를 반환하기때문에, 그 반환물을 사용하는 후속절차 필요
❌ Statement → so if you want to execute return, use 'return'keyword to make 'return statement'.
→ Statement는 특정한 문장(=return문)을 사용하지 않는 이상, 자동으로 반환하지 않음
- Assignment Expression := vs Statement =
└ Expression := 할당 및 반환
└ Statement = 할당
print(a = 3) # Err = statement
print(a := 3) # 3 := operator → print(할당 및 반환)
print(a += 1) # Err += statement
print(a + 1) # 4 + operator → print(연산 및 반환)* 거창하게 단어 VS 구문으로 비유를 하긴했지만, 실질적으로 반환하냐/마냐 차이...
* 그래도, Expression과 statement구분에 너무 집착하지 않아도 될 이유?
→ 언어마다 쬠 달라서?'C define the = operator as an expression, rather than a statement as is Python's way.'
참고:
Stackoverflow - Does anyone have a good definition of expressions and statements and what the differences are?
PEB572 - Differences between assignment expressions and assignment statements
클리앙 - [현프-1] 표현식, 표현식 문, 그리고 표현식 문 기반 언어
~ 4. 구문Statement & 식Expression 끝 ~
# [구문→문장] # [식→단어] : 정의/분류 & 차이
5. 입력/출력
⑴ 사용자 입력
- Function : input('■')
1. [출력] '■' 인자(string type) 콘솔 출력 : 입력을 안내하는 용도로 사용
2. [인풋] 사용자로부터 입력받기 - 사용자는 입력 후 Enter
3. [리턴] return (str) 입력받은 값을 value로 하는 str형 객체
+ Function 전체종료 : exit()
⑵ 콘솔 출력
- Function : print(expression)
≠ return : Keyword → Object - 반환문의 키워드일 뿐, 콘솔과 관련없음
~ 5. 입력/출력 끝 ~
# [입력] input('str') & # [출력] print(···)
6. 읽기/쓰기
with open('폴더명/파일명', 'r=읽기 or w=쓰기', 'encoding=인코딩방식') as 결과물명:
SUITE[안은문장] with EXPRESSION as TARGET:
[안긴문장] open(file, mode='r', buffering=-1, encoding=None, ···) *kor설명
└ return, 파일과 상응하는 객체:Open file and → return a corresponding file object(=file-like objects, streams)
└ ① file : 열려는 파일의 주소(path-like object) → 예:같은 폴더-'파일명.종류' 다른 폴더-'폴더명/파일명.종류'
└ ② mode : 해당 파일을 여는 방식 - 기본모드 'r' & 't'


└ ④ encoding : 텍스트 모드('t')가 들어가는 경우, 파일을 인코딩/디코딩하는 방식 - 기본값 'ASCII' → 자주 쓰는 값'UTF-8'
└ 관련함수 : 특정객체.read()
└ Return (str) 해당 객체의 내용 전체를 변환한 문자열-읽은 영역 휘발
with open('data/chicken.txt', 'r', encoding='UTF-8') as txt:
print(txt.read())
"""
1일: 815400
2일: 798000
3일: 269200
:
"""
print(type(txt.read())) # <class 'str'> : 다 읽고 남은 ''을 확인한 것
# 두 명령을 바꾸면, 아무것도 출력되지않음 → type 확인할 때, 다 읽고 휘발되어서└ 관련함수 : 특정객체.readline()
└ Return (str) 해당 객체를 한 줄씩을 변환한 문자열-읽은 영역 휘발
with open('data/chicken.txt', 'r', encoding='UTF-8') as txt:
print(type(txt.readline())) # <class 'str'> : '1일: 815400\n' 확인
print(txt.readline()) # 2일: 798000\n
print(txt.readline()) # 3일: 269200\n└ 관련함수 : 특정객체.readlines()
└ Return (list) 해당 객체의 한줄한줄을 각각의 item으로 한 리스트-읽은 영역 휘발
with open('data/chicken.txt', 'r', encoding='UTF-8') as txt:
print(txt.readlines()) # ['1일: 815400\n', '2일: 798000\n', '3일: ···]
print(type(txt.readlines())) # <class 'list'> : list=[] 확인
# 두 명령을 바꾸면, txt.readlines() → list=[] 왜냐하면, type확인할 때 다 읽고 휘발됨- 읽는 용도로 wrap된 객체를 사용하면, 사용한 줄만 휘발되는 것이 신기했다 → .readline()의 존재의의가 느껴짐
⑴ 파일읽기 → open('mode=r')
- 1. 읽기에 필요한 '치킨집 매출.txt' 만들어보기
# [치킨집 매출 리스트 만들기]
import random
for i in range(1, 31, 1):
print(f"{i}일: {random.randint(1000,9999)*100}")- 2. 읽는 용도로 wrap된 객체, 콘솔에 출력하기
└ [문제] 개행(enter, \n)의 중복 : 문서 자체의 개행뿐만 아니라 print()도 개행을 하는 바람에 두 줄 띄어짐
# 1. 그냥 print :
with open('data/chicken.txt', 'r', encoding='UTF-8') as txt:
for line in txt: # 한 줄 : "문자열1··\n"
print(line) # + print의 개행
"""
1일: 815400
2일: 798000
3일: ···
"""└ [해결1.] 문서 자체의 개행 제거 → 문자열.rstrip() : "", "\n", "\t"같은 모든 공백(whitespace)제거
# 2. 문자열.공백제거() - 공백 中 우측만 제거
with open('data/chicken.txt', 'r', encoding='UTF-8') as txt:
for line in txt: # 한 줄 : "문자열1··\n"
print(line.rstrip()) # 오른쪽 공백제거
"""
1일: 815400
2일: 798000
3일: ···
"""└ [해결2.] print()의 개행 제거 → end=""
# 3. print 개행 무시 :
with open('data/chicken.txt', 'r', encoding='UTF-8') as txt:
for line in txt: # 한 줄 : "문자열1··\n"
print(line, end="") # print()의 공백제거
"""
1일: 815400
2일: 798000
3일: ···
"""사용한 것 정리+α
▶ 문자열.lstrip/rstrip/strip()
└ 왼쪽/오른쪽/양쪽에 존재하는 whitespace( "", "\n", "\t")를 제거해주는 메소드
└ Return, (str) 해당 문자열의 공백을 제거한 새로운 문자열
▶ 문자열.split('□')
└ 해당 문자열을 □을 기준으로 나눈 후, 각각을 item으로 하는 리스트를 생성하는 메소드
└ 0 argument Return, (list) 해당 문자열을 모든 종류의 공백을 기준으로 나눈 리스트
└ 1 argument Return, (list) 해당 문자열을 □을 기준으로 나눈 리스트
my_string = "1, 2, 3" # 숫자 + 컴마 + 공백
print(my_string.split(",")) # 컴마로 나눔 → item = 숫자 / 공백 + 숫자
# ['1', ' 2', ' 3']
print(my_string.split(", ")) # 컴마 + 공백 으로 나눔 → item = 숫자
# ['1', '2', '3']
full_name = "Kim, Yuna"
print(full_name.split(",")) # ['Kim', ' Yuna']
print(full_name.split(", ")) # ['Kim', 'Yuna']
name_data = full_name.split(", ")
print(name_data[1], name_data[0]) # Yuna Kim
white_space = " \n\n 1 \t 2 \n 3 4 5 \n\n" # whitespace의 향연
list1 = white_space.split() # 인자를 넘겨주지않으면, 모든 공백기반으로 나눔
# ['1', '2', '3', '4', '5']
print(list1[0] + list1[4]) # 211 → items = 숫자모양의 문자str
print(int(list1[0]) + int(list1[4])) # 6 → 형변환 int(■)▶ end="□"
└ print(■)에 사용할 수 있는 인자 : print()의 개행을 하지말고, □를 붙일 것
⑵ 파일쓰기 → open(mode='w').write()
▶ wrap된객체.write('ㅁ')
└ 해당 객체에 입력받은 값을 기록해주는 메소드
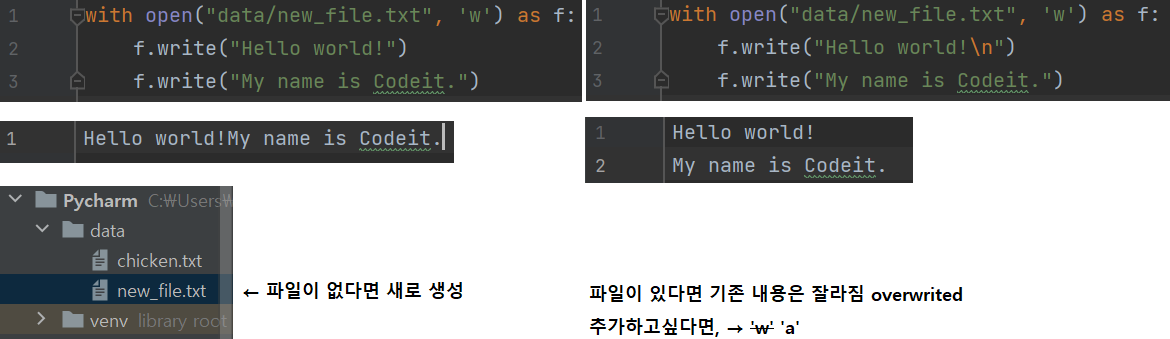
- 손수 개행('\n')을 해주어야 함
- 기존 파일에 덧붙이고 싶은 경우, open('mode=a').write → append(덧붙임, 첨부)
~ 6. 읽기/쓰기 끝 ~
# [읽기, 쓰기w] for □ in ★에 사용 .read() 전체 .readline() 한줄씩 .readlines() 리스트
7. Style guide:PEP8
PEP8 Style Guide for Python Code
[ A Foolish Consistency is the Hobgoblin of Little Minds : 융통성을 가지자 ]
- 가독성은 중요하고 가이드라인은 가독성을 강화하기위해 만들어졌지만, 그렇지 않을 때도 있고 되려 상황을 악화시킬 때도 있다.
- 그러니, 상황에 맞게 최선의 판단을 하기 !
⑴ 들여쓰기
- 들여쓰기 수준의 단위, 4 spaces = 1 tab
- 들여쓰는/내어쓰는 이유 → 의미의 연속 : ① Header-Suite [하나의 구문] ② [하나의 logical line]이지만, 물리적으론 긴 경우
└ ② 한 줄 당, '약 79자' = 물리적 한계 → 하나의 logical line을 형성하나, 물리적으로 너무 길면 개행 & 들여쓰기
└ 구분자(delimiters: 괄호, 따옴표, 쉼표 등), 연산자 단위로 개행 : Opening 구분자/쉼표/이항연산자 개행
└ 그냥 개행 + 들여쓰면 안되는 경우, backspace(\) 필요 : \ + 개행 + 들여쓰기
# Opening 구분자 개행 - 4칸 들여쓰기
foo = long_function_name(
var_one, var_two,
var_three, var_four)
def long_function_name(
var_one, var_two, var_three,
var_four):
my_list = [
1, 2, 3,
4, 5, 6
]
my_list = [
1, 2, 3,
4, 5, 6
]# Opening 구분자 개행 - an extra level of indentation
# ♥ Correct:
def long_function_name(
var_one, var_two, var_three,
var_four):
print(var_one)
if (this_is_one_thing
and that_is_another_thing):
do_something()
# ▼ Wrong: Header를 평소처럼 4칸 개행하면, Suite절과 구분이 안 감
def long_function_name(
var_one, var_two, var_three,
var_four):
print(var_one)# 쉼표 개행
# ♥ Correct: 여는 구분자 '(' 와 vertical 개행수준 맞추기
foo = long_function_name(var_one, var_two,
var_three, var_four)
# ▼ Wrong: 단순하게 4칸 들여쓰면, 첫 줄의 함수 인자들이 눈에 안 띄어서 가독성 저하
foo = long_function_name(var_one, var_two,
var_three, var_four)# 이항연산자 개행
# ♥ Correct: 이항연산자를 시작으로 하는 vertical 정렬
income = (gross_wages
+ taxable_interest
+ (dividends - qualified_dividends)
- ira_deduction
- student_loan_interest)
# ▼ Wrong: 연산자와 엮인 두 항의 관계가 눈에 잘 띄지 않음 = 가독성 저하
income = (gross_wages +
taxable_interest +
(dividends - qualified_dividends) -
ira_deduction -
student_loan_interest)# Docstring의 개행 : 마지막 줄엔 닫는 따옴표만 존재
def foo():
"""A multi-line
docstring.
"""
def bar():
"""
A multi-line
docstring.
"""# 그냥 개행 + 들여쓰기하면 안 됨 → \ 사용
with open('/path/to/some/file/you/want/to/read') as file_1, \
open('/path/to/some/file/being/written', 'w') as file_2:
file_2.write(file_1.read())
⑵ import
- 위치 : [파일 최상단] 주석 및 docstrings - import - global variables/constants
- import는 하나 당 한 줄, from으로 묶으면 여러 개 한 줄
- Standard library / third party / local application/library로 그룹화 가능 → 그룹은 '빈 줄'로 구분
# ♥ Correct:
import os
import sys
from subprocess import Popen, PIPE
# ▼ Wrong:
import sys, os
⑶ 공백:whitespace
- 괄호 전/후 공백 無
- comma(,) semicolon(;) colon(:) 후 공백
└ ★ comma(,) semicolon(;) colon(:) 다음이 바로 괄호이면, 후 공백 삭제
└ ★ Slicing의 colon(:)은 이항연산자처럼 작동, 전/후 공백 or 전/후 공백 無
- 이항연산자 전/후 공백 + 연산순위에 따른 공백삭제OK
- = 전/후 공백 + ★ keyword or optional parameter지정의 경우, 전/후 공백 無
- 하나의 절, 문은 한 줄에 쓸 수 있더라도 개행 분리 必
# 괄호 전/후 공백無
# ♥ Correct:
spam(ham[1], {eggs: 2})
spam(1)
dct['key'] = lst[index]
foo = (0,)
# ▼ Wrong:
spam( ham[ 1 ], { eggs: 2 } )
spam (1)
dct ['key'] = lst [index]
foo = (0, )# , ; : 후 공백 & 이항연산자 전/후 공백
# ♥ Correct:
x = 1
y = 2
long_variable = 3
if x == 4: print x, y; x, y = y, x
# ▼ Wrong:
x = 1
y = 2
long_variable = 3
if x == 4 : print x , y ; x , y = y , x# Slicing에 쓰이는 : 전/후 공백 or 양쪽 공백 無
# ♥ Correct:
ham[1:9], ham[1:9:3], ham[:9:3], ham[1::3], ham[1:9:]
ham[lower:upper], ham[lower:upper:], ham[lower::step]
ham[lower+offset : upper+offset]
ham[: upper_fn(x) : step_fn(x)], ham[:: step_fn(x)]
ham[lower + offset : upper + offset]
# ▼ Wrong:
ham[lower + offset:upper + offset]
ham[1: 9], ham[1 :9], ham[1:9 :3]
ham[lower : : upper]
ham[ : upper]# 이항연산자 전/후 공백이지만, 연산先순위에 의한 공백삭제OK
# ♥ Correct:
i = i + 1
submitted += 1
x = x*2 - 1
hypot2 = x*x + y*y
c = (a+b) * (a-b)
# ▼ Wrong:
i=i+1
submitted +=1
x = x * 2 - 1
hypot2 = x * x + y * y
c = (a + b) * (a - b)# = sign이 keyword argument나 optional parameter을 만드는 경우, 양쪽 공백 無
# ♥ Correct:
def complex(real, imag=0.0):
return magic(r=real, i=imag)
# ▼ Wrong:
def complex(real, imag = 0.0):
return magic(r = real, i = imag)# 하나의 절, 문은 전부 개행으로 분리
# ♥ Correct:
if foo == 'blah':
do_blah_thing()
do_one()
do_two()
do_three()
# ▼ Wrong:
if foo == 'blah': do_blah_thing()
do_one(); do_two(); do_three()
for x in lst: total += x
while t < 10: t = delay()
try: something()
finally: cleanup()
do_one(); do_two(); do_three(long, argument,
list, like, this)
if foo == 'blah': one(); two(); three()
⑷ 주석
- 코드 수정에 따라 꾸준히 업데이트 할 것
- Inline 주석은 가독성을 해치므로 코드만 읽어도 알만한 obvious한 첨언은 지양하고, 도움되는 속뜻은 OK
⑸ 프로그래밍 상 추천
- ··· is not ··· 추천, not ··· is 보다
- try절:최대한 minimum하게, except절:err 명확하게 짚어주기, finally절: flow control문(return, continue, break)X
- string method가 더 빠름, module보다
- True, False와의 == 비교 X
└ if x == True: → if x:
~ 7. Style guide 끝 ~
'Computer science : 컴퓨터과학 > Student story at 혼긱' 카테고리의 다른 글
| [명품C++] 1장 C++시작_ 연습문제 실습문제 해설 (0) | 2022.03.25 |
|---|---|
| 인공지능에 대한 생각 (0) | 2022.03.24 |
| 4. Python 응용하기 (1) | 2021.06.17 |
| [+복습(2)] 3. 프로그래밍과 데이터 中 값 관련 함수 & 메소드 (1) | 2021.05.27 |
| [+복습(1)] 3. 프로그래밍과 데이터 中 자료형분류와 가변성 (0) | 2021.05.14 |
블로그의 정보
노력하는 실버티어
노실언니